
Securing a Bad Blogging Platform Dec. 1, 2016 in Cybersecurity, Php, Text, University, Web
I was tasked with securing $BloggingPlatform. Here are my findings.
I was tasked with securing $BloggingPlatform. Here are my findings.
I decided to investigate Machine Learning using MATLAB.
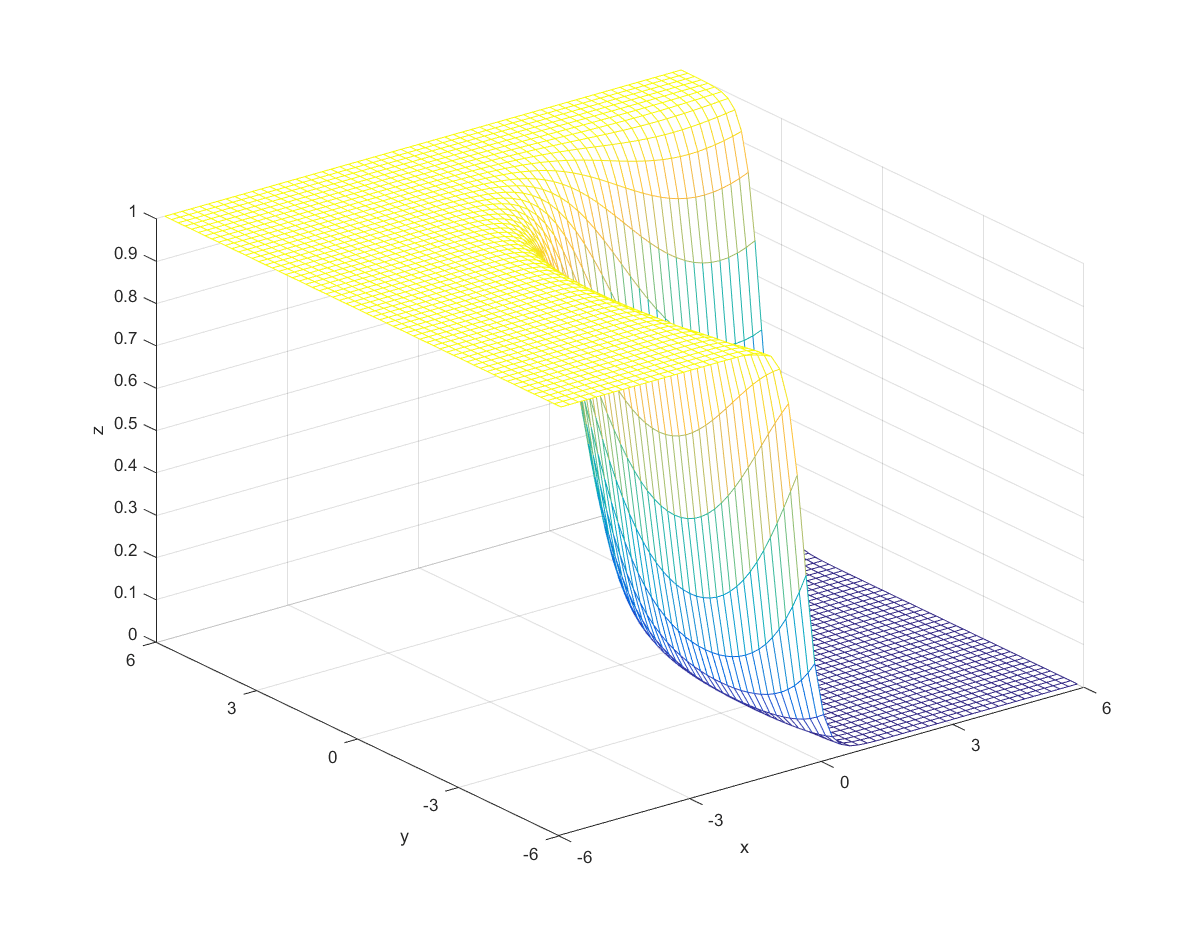
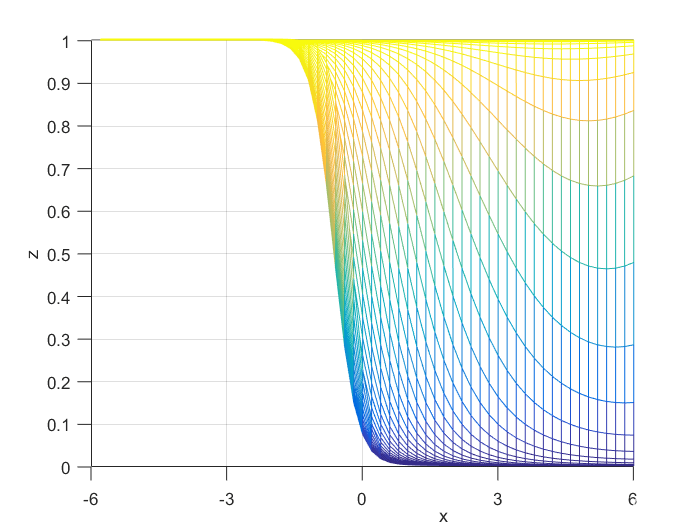
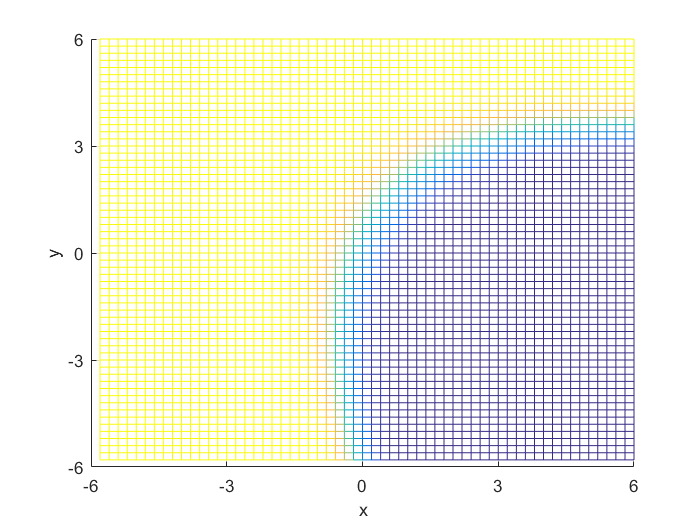
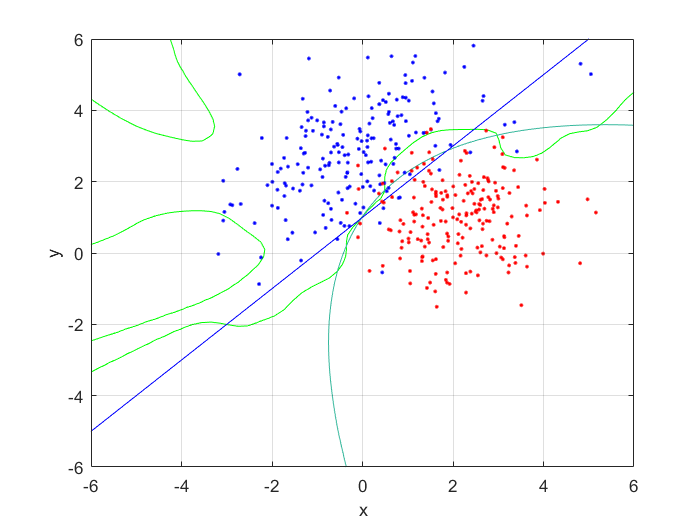
To compute the posterior probability, I started by defining the following two Gaussian distributions, they have different means and covariance matrices.

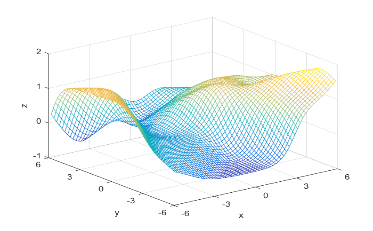
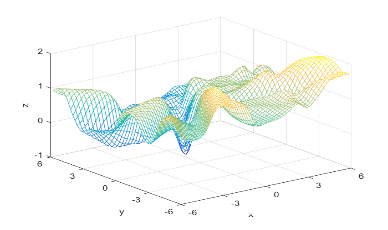
Using the definitions, I iterated over a N×N matrix, calculating the posterior probability of being in each class, with the function mvnpdf(x, m, C); To display it I chose to use a mesh because with a high enough resolution, a mesh allows you to see the pattern in the plane, and also look visually interesting. Finally, I plotted the mesh and rotated it to help visualize the class boundary. You can clearly see that the boundary is quadratic, with a sigmodal gradient.
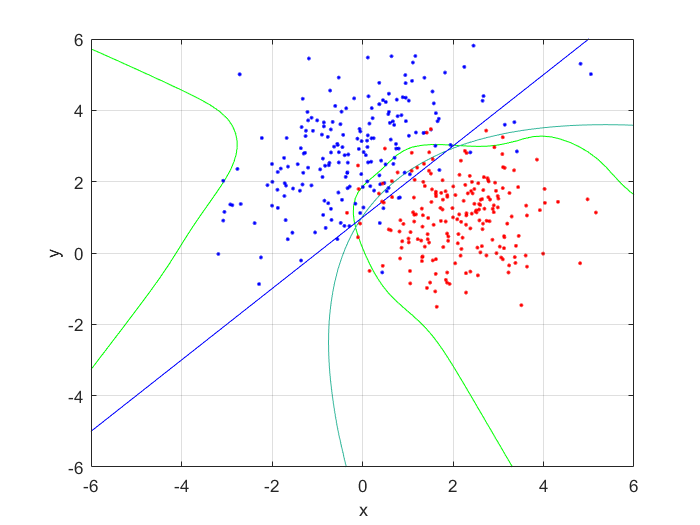
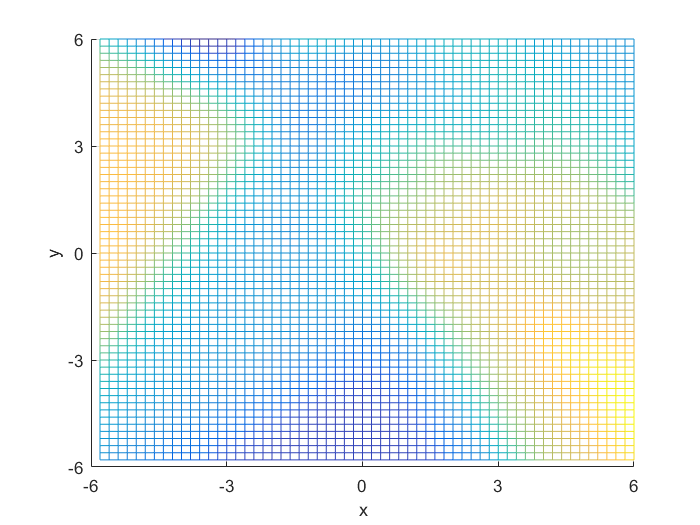
Next, I generated 200 samples with the definitions and the function mvnrnd(m, C, N);, finally partitioning it half, into training and testing sets. With the first of the sets, I trained a feed-forward neural network with 10 hidden nodes; with the second, I tested the trained neural net, and got the following errors:
These values are both small, and as the testing error is marginally larger than the training error, to be expected. This shows that the neural network has accurately classified the data.
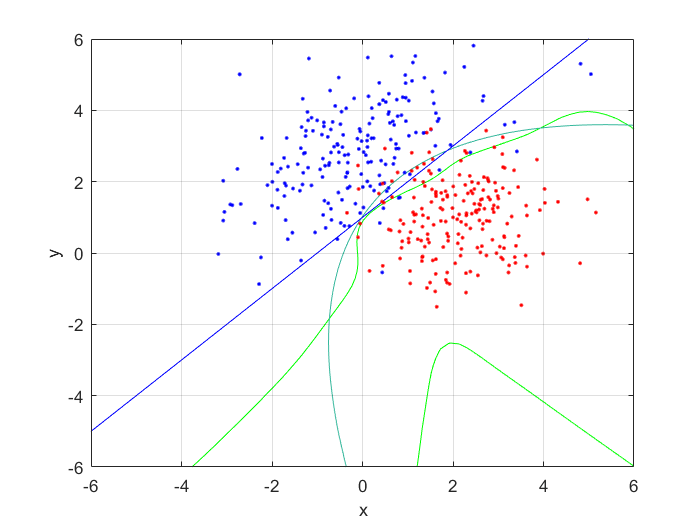
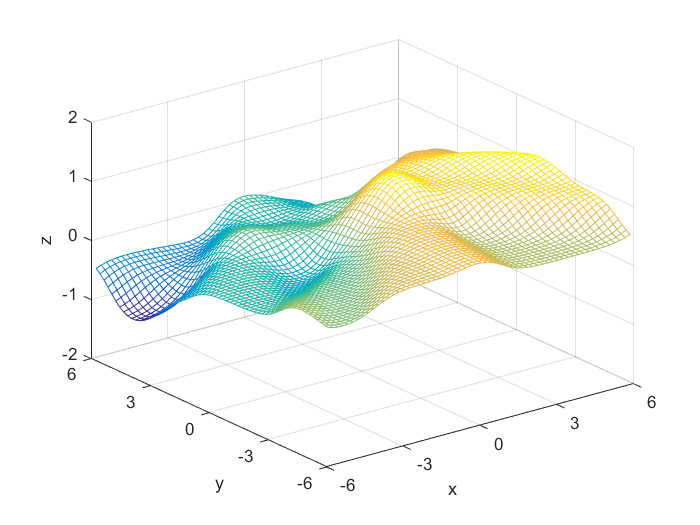

I compared the neural net contour (At 0.5) to both a linear and quadratic Bayes’ optimal class boundary. It is remarkable how significantly better Bayes’ quadratic boundary is. I blame both the low sample size, and the low number of hidden nodes. For comparison, I have also included Bayes’ linear boundary, it isn’t that bade, but still pales in comparison to the quadratic boundary. To visualize, I plotted the neural net probability mesh. It is interesting how noisy the mesh is, when compared to the Bayesian boundary.
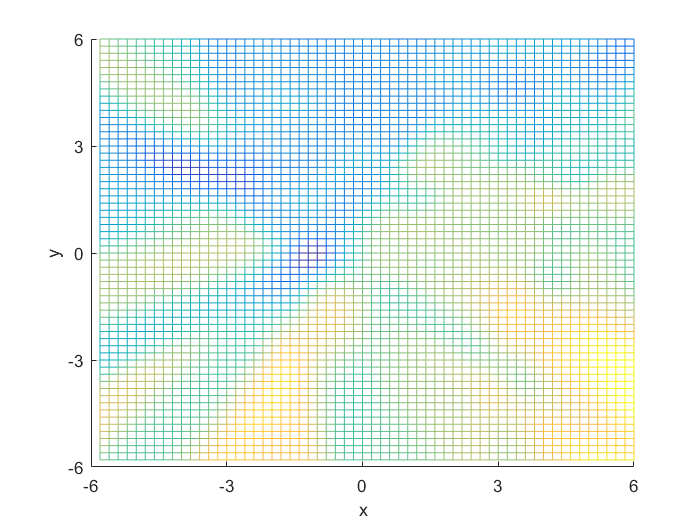
Next, I increased the number of hidden nodes from 10, to 20, and to 50. As I increased the number of nodes I noticed that the boundary became more complex, and the error rate increased. This is because the mode nodes I added, the more I over-fitted the network. This shows that it’s incredibly important to choose the network size wisely; it’s easy to go to big! After looking at the results, I would want to pick somewhere around 5-20 nodes for this problem. I might also train it for longer.
I was set the task of first generating a number of samples from the Mackey-Glass chaotic time series, then using these to train and try to predict their future values using a neural net. Mackey-Glass is calculated with the equation:

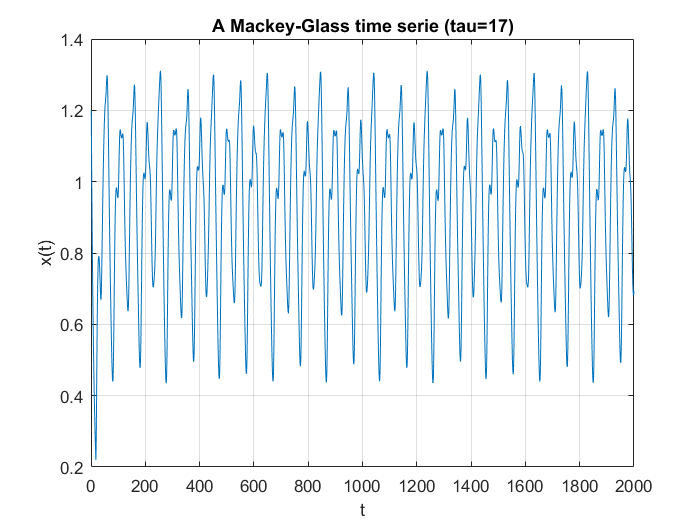
For the samples, I visited Mathworks file exchange, and downloaded a copy of Marco Cococcioni’s Mackey-Glass time series generator: https://mathworks.com/matlabcentral/fileexchange/24390. I took the code, and adjusted it to generate N=2000 samples, changing the delta from 0.1 to 1. If I left the delta at 0.1, the neural network predicted what was essentially random noise between -5 and +5. I suspect this was due to the network not getting enough information about the curve, the values given were too similar. You can see how crazy the output is in the bottom graph. Next, I split the samples into a training set of 1500 samples, and a testing set of 500 samples. This was done with p=20. I created a linear predictor and a feed-forward neural network to look at how accurate the predictions were one step ahead.

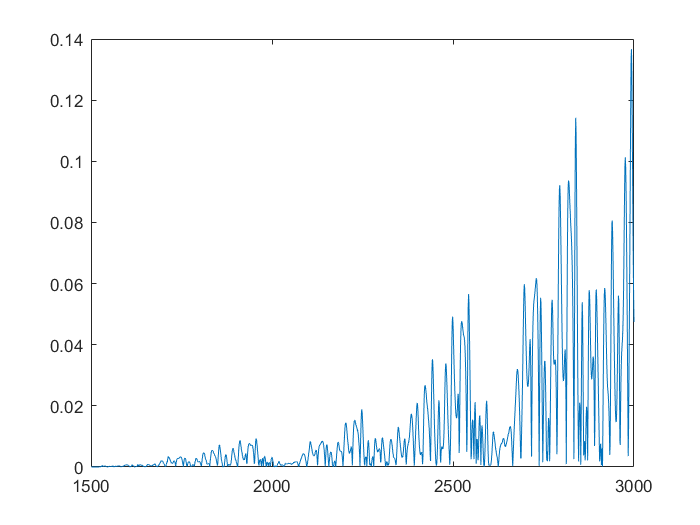
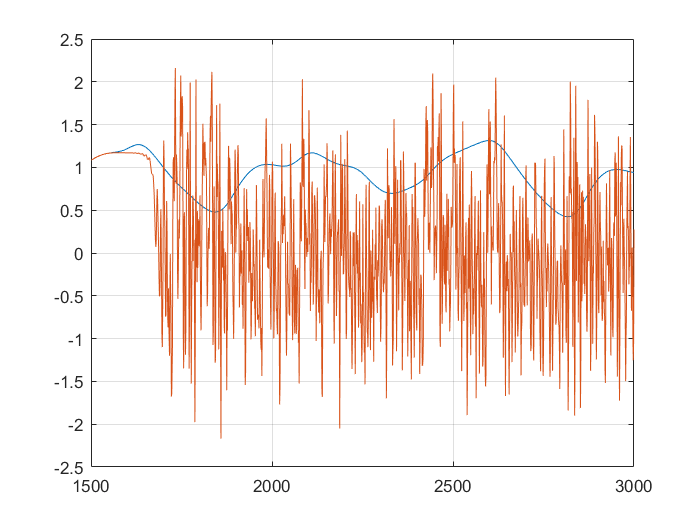
This shows that the neural network is already more accurate, a single point ahead. If you continue, feeding back predicted outputs, sustained oscillations are not only possible, the neural net accurately predicts values at least 1500 in the future. In the second and third graphs, you can notice the error growing very slowly, however even at 3000, the error is only 0.138
Using the FTSE index from finance.yahoo.com, I created a neural net predictor capable of predicting tomorrows FTSE index value from the last 20 days of data. To keep my model simpler and not over-fitted, I decided to use just the closing value, as other columns wouldn’t really affect the predictions, and just serve to over-complicate the model.
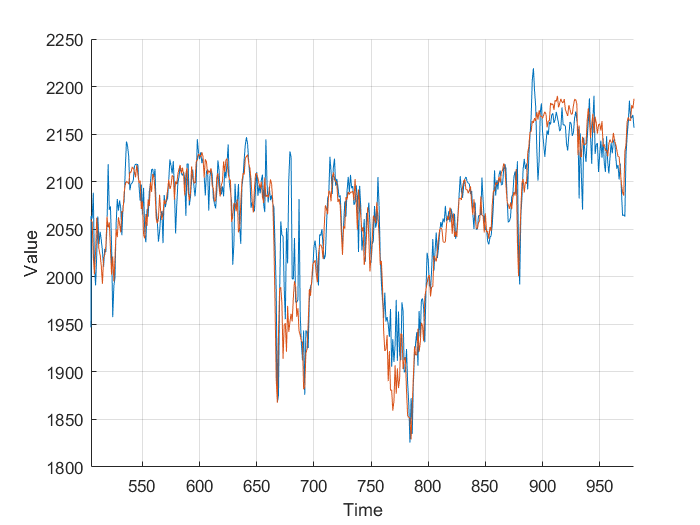
Feeding the last 20 days into the neural net produces relatively accurate predictions, however some days there is a significant difference. This is likely due to the limited amount of data, and simplicity of the model. It’s worth taking into account that the stock market is much more random and unpredictable than Mackey-Glass.
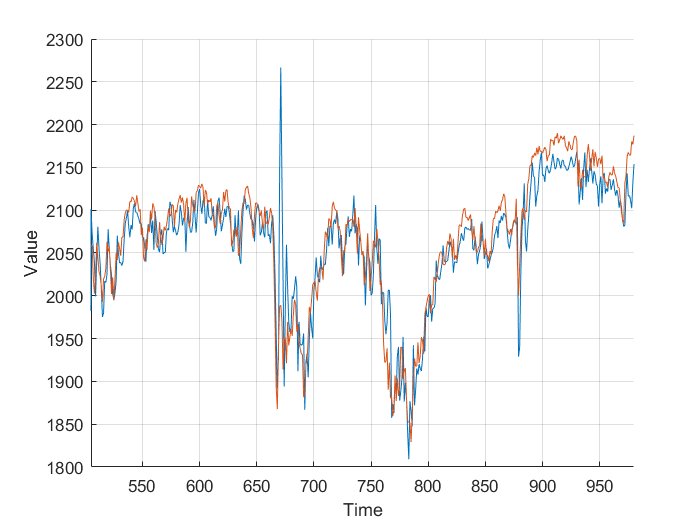
Next I added the closing volume to the neural net inputs, and plotted the predictions it made. Looking at the second graph, it’s making different predictions, which from a cursory glance, look a little more in-line.
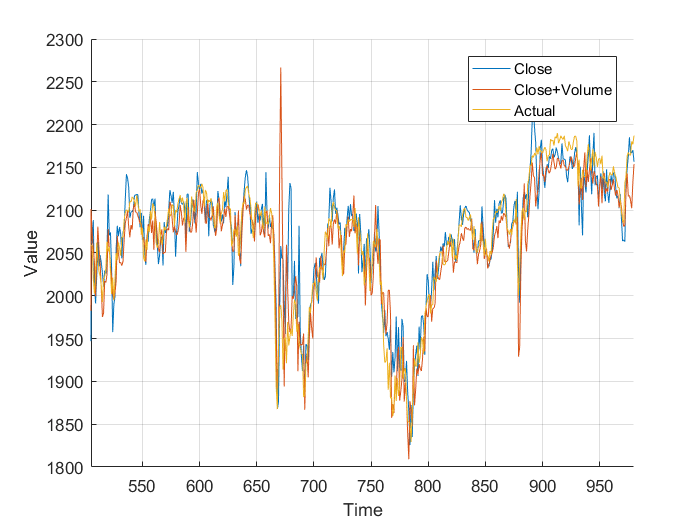
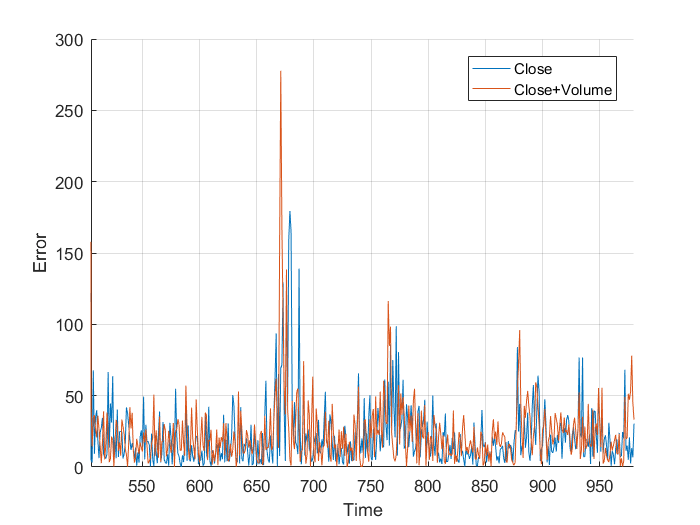
However, I wasn’t sure so I plotted them on the same axis, and, nothing really. It just looks a mess. Plotting the different errors again gives nothing but a noisy, similar mess. Finally, I calculated the total area, the area under the graph and got:
This is nothing, a different of 0.011×10^5 is nothing when you are sampling 1000 points. It works out to an average difference of 1.131, or 0.059%. From this I, can conclude that the volume of trades has little to no effect on the closing price, at least when my neural network is concerned. All that really matters is the previous closing values.
Overall, there is certainly an opportunity to make money in the stock market, however using the model above, I wouldn’t really want to make big bets. With better models and more data, you could produce more accurate predictions, but you still must contest with the randomness of the market. I suggest further research before betting big.

A Jison, DnD-style dice roller. Type then it will automatically roll. Supports arithmetic, keeping high/low dice, and fudge dice.
npm install fantasy-dice [-g]
roll 4d6h3
echo -e "var dice = require('fantasy-dice');\nconsole.log(dice("4d6h3"));" > dice.js
node dice.js
I’ve made a rudimentary gopher client using Java and JavaFX. Download from GitHub.
My (mostly failed) attempt at creating a NES Emulator from scratch.
This is the user manual for the Aqua programming language created as part of Programming Languages and Concepts. Visit the project on Github.
Aqua is a C-like imperative language, for manipulating infinite streams. Statements are somewhat optionally terminated with semicolons, and supports both block ( /* ... */) and line comments ( // ...).Curly brackets are used optionally to extend scope. Example code can be found in the Appendices.
Before continuing, it’s helpful to familiarise yourself with Extended BNF. Special sequences are used to escape.
Once the interpreter has been compiled using the make command, you can choose to run an interactive REPL or a stored program. Executing ./mysplinterpreterwith no arguments will start in an interactive REPL . You should save your program files as <filename>.spl and pass the location as the first argument to ./mysqlinterpreter. As data is read from standard in, you can pipe files in using the < operator, or pipe programs in using the | operator, allowing you to create programs that manipulate infinite streams.
./mysplinterpreter./mysplinterpreter <file> [ < <input> ]<program> | ./mysplinterpreter <file>Programs are executed in multiple stages:
Whilst abroad I put Microsoft Hyperlapse to the test, first in Singapore, then in New Zealand.
 Riding the Singapore Mass Rapid Transit system (4x Hyperlapse)
Riding the Singapore Mass Rapid Transit system (4x Hyperlapse)
 Driving around Auckland (16x Hyperlapse)
Driving around Auckland (16x Hyperlapse) After our trip to , we spend some










This year I returned to New Zealand. Last time, I explored the country on a road trip, this time, I explore the North Island, and spend time with family.















































This week I had the pleasure of competing in the CodeCon Grand finals at Bloomberg’s London headquarters. While unfortunately I didn’t do that well, visiting the headquarters and exploring London was great fun. I didn’t take any pictures inside the event, I thought I would share a few photos taken on during my trip.


The day after the competition, I left the hotel and set of through the city. The Museum of London was nearby, so I checked it out. While there it started raining and a rainbow appeared. Then, a quick walk lead me to St. Paul’s.


While, crossing the Millennium Bridge I took two panoramas of the Thames. Unfortunately the day was overcast, and so the pictures are rather gray.

Finally ending my trip inside the Tate Modern where I saw Abraham Cruzvillegas Empty Lot filling the Turbine room.
On the first day of renting, My landlord gave to me: A junk pile in the garden.
On the second day of renting, My landlord gave to me: Two dark toilets, And a junk pile in the garden.
On the third day of renting, My landlord gave to me: Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the fourth day of renting, My landlord gave to me: Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the fifth day of renting, My landlord gave to me: Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the sixth day of renting, My landlord gave to me: Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the seventh day of renting, My landlord gave to me: Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the eighth day of renting, My landlord gave to me: Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the ninth day of renting, My landlord gave to me: Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the tenth day of renting, My landlord gave to me: Ten disturbances, Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the eleventh day of renting, My landlord gave to me: Eleven cracks tears and bumps, Ten disturbances, Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the twelfth day of renting, My landlord gave to me: Twelve quid less a day, Eleven cracks tears and bumps, Ten disturbances, Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
Grabble is a fast-paced word game where players take it in turns to flip over tiles, form words, and steal words from other players. I was taught the game by Samson Danziger, and I am writing this as from a brief search, there is little information on it.
If missing a set of Scrabble tiles, any similar set of letter tiles will do, or they can bought for a few quid from many online retailers.
It is recommended that a dot, question mark, or asterisk is added using a permanent marker to one face of each wild-card to reduce confusion when turned over.
Players turn over tiles one at a time trying to form words at least three tiles long, extend existing words, or steal words from an opposing player. When successful, that player is now the next player to turn over a tile.
T E A, another player can claim E A T. If the first player is clever they can then claim A T E to claim it back.The game ends when all tiles are flipped and players agree that no more words can be improved or rearranged. This should not take longer than a couple of minutes. Players can enter and exit the game at any time, simply watch the game until they can get a word of their own. If they wish to leave, words remain in play and other players can steal the words when possible.