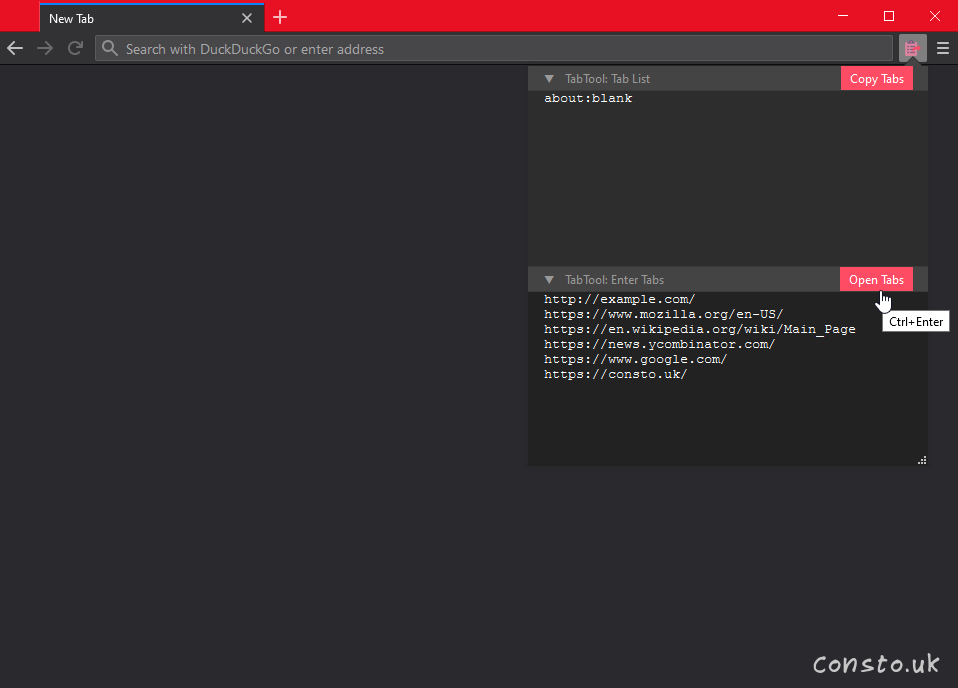
Earlier this month I recorded the BathTub Orchestra performing at Christ Church in Bath, but when I went to edit the video so I could upload it to YouTube, there was a distracting flickering in the top left and top right of the screen! I’ve been using the powerful Davinci Resolve, and while it does have a deflickering filter, it unfortunately is a paid feature.
Fortunately, the free and open-source Avisynth+ can be used to quickly remove the flicker. These are the steps that worked for me, and I’m writing them down in case I ever need to make use of the them again. Hopefully someone out there finds them helpful.
(Optionally) download and install the latest version of AvsPmod from https://github.com/gispos/AvsPmod/releases, the AviSynth+ and plugins folders may need to be updated
Using AvsPmod or any text editor to create a file named deflicker.avs containing something like:
About a year ago I purchased myself a brand-new Acer Triton 500 gaming laptop. It has overall been a great purchase, and I especially love the 144Hz IPS display paired with a powerful graphics card. However, in the time I have had it, I have twice had the Killer WiFi and Bluetooth stop working with a Code 10 error message. Fortunately, there is a quick an easy fix! Restarting and reinstalling drivers doesn’t work; you just need to reset your BIOS.
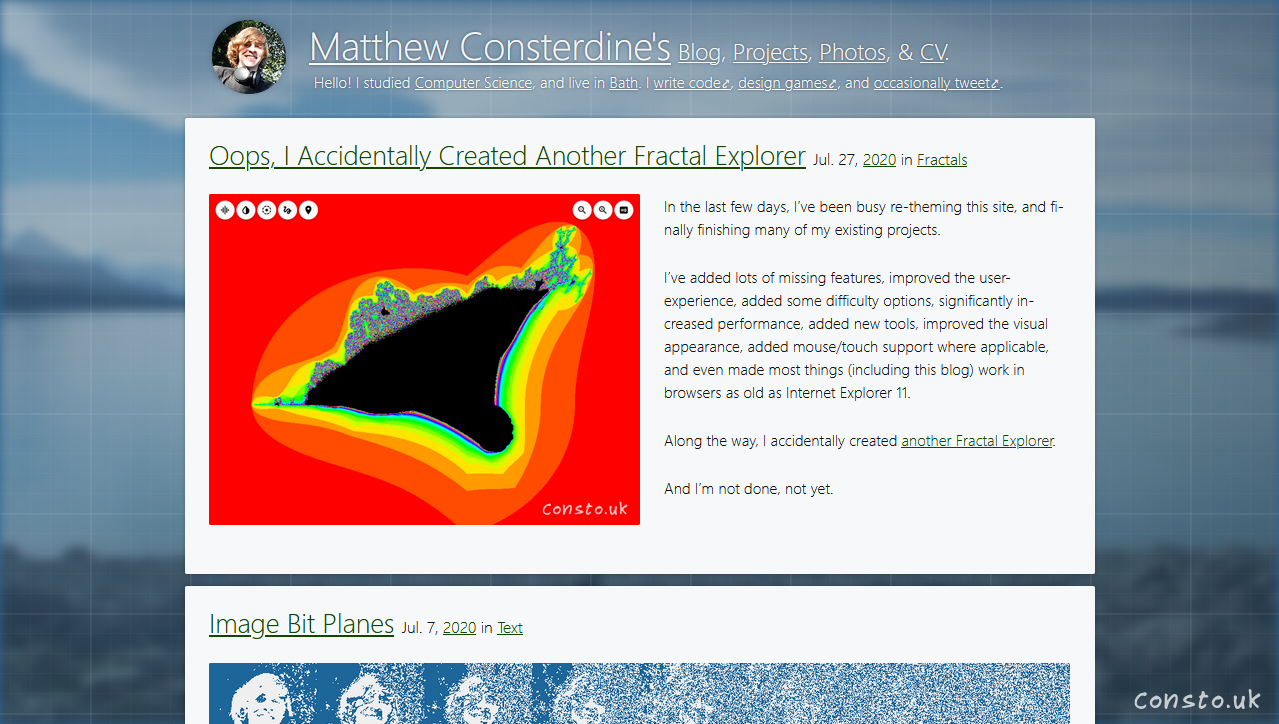
In the last few days, I’ve been busy re-theming this site, and finally finishing many of my existing projects.
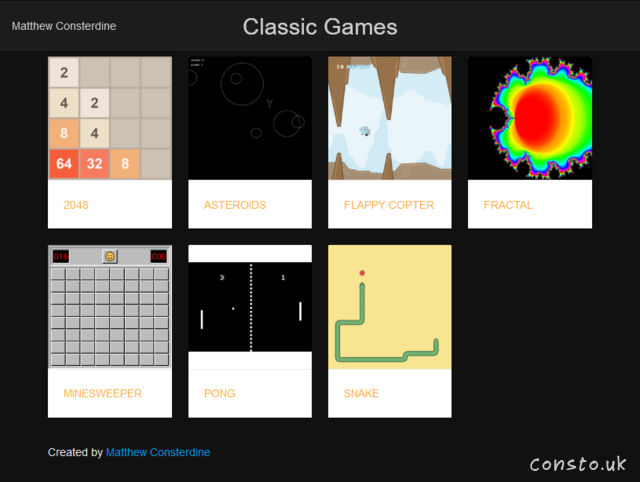
I’ve added lots of missing features, improved the user-experience, added some difficulty options, significantly increased performance, added new tools, improved the visual appearance, added mouse/touch support where applicable, and even made most things (including this blog) work in browsers as old as Internet Explorer 11.
Jekyll is fantastic, easy to use, and extensible. However, some Jekyll hosts such as GitHub Pages do not allow people to use custom plugins - and I want category and year pages. But rightly so. Allowing custom plugins would require hosts to allow users to run arbitrary Ruby code on their build servers and possibly create a mess. This problem is solvable, but it’s ultimately simpler to just ban them entirely.
This constrained environment forces you to get creative. On this blog I use the fantastic jekyll-compress-html template which minifies the very post you are reading. I have written by own template to automatically replace standard markdown or HTML images with lazily loaded ones. And finally, I have written a small (it’s only a hundred or so lines ;) ) Makefile to automatically, among other-things, generate year and category pages:
To use, simply create _templates/category.html and a _templates/year.html templates and run make cat year. The code assumes your posts start with the date and they are stored in the default _posts/. When run #####CATEGORY##### and #####YEAR##### will be replaced with the templated value.
Tittle-Tattle Town is a game where players travel around a small game board graph, and gossip about other players. Each player has a small deck of identically-backed cards, one for each player, and a crib sheet. Start on your starting tile, and collect two gossip tokens.
On your turn, roll the dice, and move up to that many spaces. If you can move you must move. If you land on an occupied space, you must tattle with one person of your choosing on that space.
Tattling: Briefly talk to another player, then secretly choose one of your player cards. Reveal simultaneously. If you…
This year I am going to take part in the 2018 Advent of Code, where each day, two new programming challenges are uploaded to the site. But as I live in the UK and I don’t want to ruin my sleeping schedule for a month, competing for the leaderboard is out of the question. Instead, I am going to challenge myself to use 25 different programming languages.
For this I will treat different versions of the same language as the same language, so no Python 2 and Python 3 solutions. However, I can use C, C++, and C# as they are all different languages, even if they are rather similar syntactically. As for what language I pick on the day, it really depends how I am feeling. If the problem is simple, I am more likely to choose a more complex or unfamiliar language. I’ll be saving some language for when I am really struggling.
Edit: Oops, so that didn’t happen. Not long after starting this challenge I broke my dominant wrist roller-skating, and just in time for Christmas! But anyway, this means that it is unlikely that I will finish this. While incomplete, I am glad I attempted it and will definitely consider using Rust in future projects - it is a nice language.
Reddit, the 18th largest site worldwide is a fantastic site full of fun user-created content, amazing photos from around the world, and crazy far-right conspiracy theories. The web experience is great too. On desktop you can see several posts at a time amidst a sea of extraneous white-space. On mobile the site fills your browser until it is time to nag you, at least twice, to install their app. And then touch-events are registered 1cm up the page for no good reason. Or images refuse to load no matter what you do. You get the picture.
And I find myself going back.
Other social-networks simply don’t grab me the same way that Reddit does. Reddit is a never-ending fire-hose of content, you can keep scrolling, and keep scrolling, and keep scrolling, and keep scrolling, and I do. Facebook is a useful tool, but I never find myself scrolling through the news feed. Twitter is an endless feed of announcements, politics, and small things taken out of context. LinkedIn is a professional waste of time. Twitch is background noise, I listen to it, I don’t watch it, and I don’t feel that I waste the little time I spend there. YouTube, well I spend a fair amount of time on YouTube. There are great videos published near daily, but my subscription-feed is curated, and the front-page is limited.
Reddit just keeps going.
I only have finite time in a day, in a year, in a life, and I don’t think Reddit is a good way to spend any of it. I set perpetual Cold Turkey blocks on Reddit and other distractions on my computers. I do not have a Reddit app installed on my phone, but I do have a web-browser. I try to not use Reddit on my phone, I do it anyway. I clear my history from time to time to clear Reddit from my suggestions, it comes back. I definitely need to try harder.
I think I would block Reddit entirely if I could.
As far as I know, there is no perfect method to block Reddit on a non-rooted Android phone (I like Google Pay and similar applications) like there is on a regular computer. Cold Turkey has an Android app, but it blocks the phone instead of Reddit. It is still a useful app but it’s not what I am looking for. You can use an app to setup an Accessibility, VPN, or DNS blocker but doing so is finicky. Either it needs a persistent notification, drains what little battery life my old phone has left, or needs to be configured for every single WiFi network you connect to. I recently found BlockSite which seems promising, but I am a little concerned about how easy it would be to uninstall.
This isn’t great, but there is a solution.
Reddit, you keep making your site worse on a near weekly basis. Mobile used to be fantastic, fast, and worked well. First adverts and sponsored content were added which is fair, a site needs to earn money to survive. Cookie banners came next, but they are commonly thought to be required by law (I am not a lawyer). Then the site started to nag you to install the app, which is annoying but only seemed to appear once per tab. The touch-events bug came after, stopping browsing sessions in their tracks. Next Reddit added the blue pill at the bottom of every page, it’s really annoying to close. And now, Reddit has added yet another prompt to install their app. On every page you now need to confirm that yes, you want to continue using Google Chrome. If you make a mistake, or the touch-events bug strikes you will be whisked away from your dark Reddit experience into the stark white Play store.
So thank you Reddit, and please keep up the good work.
This week I used Markov Chains to create folk music. It is output in ABC and rendered using ABCjs.
The music it makes is a little bit strange and it doesn’t really understand how many beats should be in a bar, but if that is a problem up the iterations. Keep raising the iterations and eventually you might even hear a tune that you know!
Under the hood, it is relatively simple. I started by downloaded about 300 folk tunes from Sourceforge. After making an Ajax request to load them, it “parses” each tune into a data structure that is easy to work with. Then two Markov Chains are generated for the title and for the music, the other attributes are just chosen randomly. Tunes can be played back with or without chords, and on any instrument. Click here to start.
I teased with an idea, and here is a very basic demo of it complete and released. Just a warning, it runs poorly, looks bad, and isn’t fun to play. Enjoy!
On a more serious note, while this is not the result I wanted I have definitely learned, or at least re-learned a few things. Looking over it, a project like this is likely too big for me, at my current skill level, with the short amount of time I gave myself.
Not to be confused with chess boxing, although feel free to play box chess boxing. Box chess is a new, dumb, derivative, variant of chess that we almost certainly reinvented down at the pub on a Friday night. To play take a standard chessboard. No piece is allowed to enter or pass through c3-c6, d3, d6, e3, e6, or f3-f6. The knight however can jump over the spaces and land in the center two by two square. It was fun, and strange to play. If bishops feel to week swap the blocked spaces for c4-c5, d3, d6, e3, e6, and f4-f5 to form a ring instead.
Reverse Chess!
Reverse chess is quick, simple, and deadly. Start the game with the row of pawns swapped with the back row. That is it. Unlike a regular game of chess which starts with a slow (relatively) ramp up reverse chess is action packed from the beginning. Every piece is at risk and you are one move away from being checked. I also suspect that this dumb perversion of chess could be solvable, or the start at least be optimised. What is the best first move, take a piece or check? I do not know!
Stratego Chess!
Stratego Chess is chess, played on a Stratego-like grid. The squares d2-d3, d6-d7, e2-e3, and e6-e7 are blocked out and no piece, no even the knight can enter. Unlike Stratego the pieces are not hidden, it is a mix between the two.
So, what will I make? I’m honestly not entirely sure. I am planing to start with a couple of Unity games and I am considering resuming work on some previous ideas. From there, I want to work on a lower level, and I have ideas. But, I do not only want to make games and demos. I want to experiment and make new, different things. Maybe I’ll write fiction, compose music, make art. Who knows? I don’t!
Intersection Observer is a relatively new API with decent support that can have a huge impact on performance. It has many uses and can trigger all sorts of code but this article is simply looking into performance. With it, image lazy loading can be quickly and easily added to any site including static Jekyll sites.
To start, define a variable to store the Interaction Observer. For simpler deployment, the code below avoids using modern JavaScript features such as let and arrow functions.
varobserver
Secondly, a function to load a given image. Here, a temporary image is created to load the image and if successful the source of the actual image is replaced.
But, the code above can only lazy-load images with very specific markup. This is where this nasty piece of Liquid code comes in. Liquid is fundamentally a very limited language with no direct way to initialise arrays, weird syntax, and no regular expressions. So, instead of using regular expressions, we can instead create a nasty piece of splitting code which works just well enough for the job.
The HTML Jekyll generates from Markdown is simple and regular enough for the following code to work. I would not expect it to work for more complicated HTML. But it’s worth a shot!
{%- assign excerpt = content | split: '<img src="' -%}
{%- for e in excerpt -%}
{%- if forloop.first == true -%}
{{ e }}
{%- else -%}
{%- if e contains '" alt="' -%}
{%- assign f = e | split: '" alt="' -%}
{%- assign url = f | first -%}
{%- assign g = f | shift | join: '" alt="' | split: '"' -%}
{%- assign alt = g | first -%}
{%- assign rest = g | shift | join: '"' -%}
<noscript><img src="{{ url }}" alt="{{ alt }}" /></noscript><img class="script-required" src="#" data-lazy-src="{{ url }}" alt="{{ alt }}"{{ rest }}
{%- else -%}
{%- assign f = e | split: '"' -%}
{%- assign url = f | first -%}
{%- assign rest = f | shift | join: '"' -%}
<noscript><img src="{{ url }}" /></noscript><img class="script-required" src="#" data-lazy-src="{{ url }}"{{ rest }}
{%- endif -%}
{%- endif -%}
{%- endfor -%}
Now I recommend styling the unloaded images with width and height. If known ahead of time it can be set explicitly. Failing that, I recommend setting a generic default using CSS.
img{min-width:100px;min-height:100px;}
And finally with this in place, my site often enjoys a perfect score in Google Chrome Inspector Audit. It cleanly beats google.com which has a top score of 91 and even beats motherfuckingwebsite.com in every category but performance where it draws at 100.
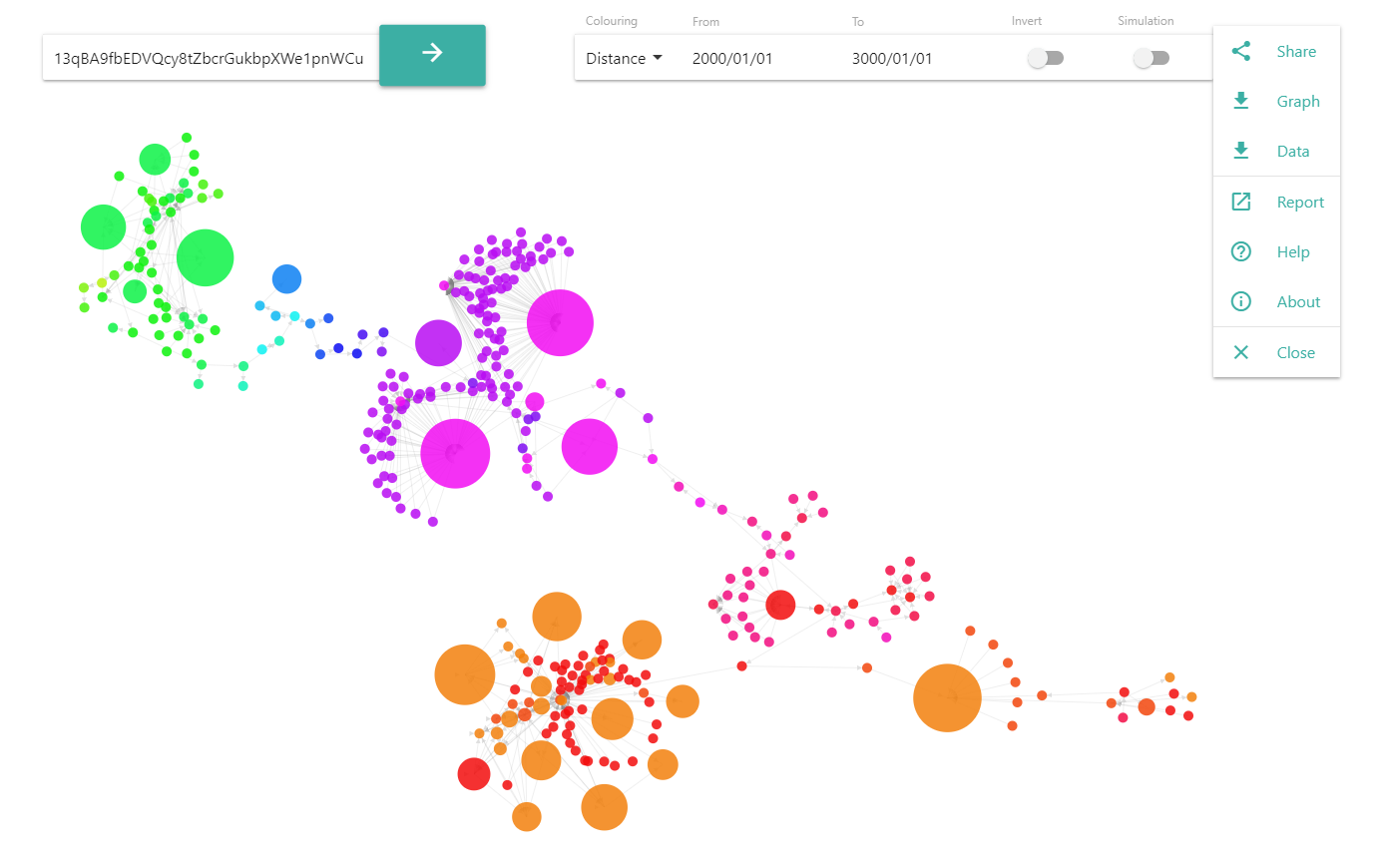
This project demonstrates the ability to visualize, and trace transactions through the Bitcoin network, evaluating three different methods. Namely poison, haircut and First-In-First-Out (FIFO).
To achieve this, a web application was created to first build up a network graph representing Bitcoin addresses as nodes, and transactions as directional edges. This allows the user to easily grasp the history of any given Bitcoin address, and then trace any transaction either up or down the graph.
By clicking on a node in the graph, the application will automatically load that address and it’s associated transactions, adding it to the graph. By hovering over a node in the graph, the tool-tip on the right will appear. It displays a number of useful statistics about the address, and gives the user the option to trace transactions by clicking on any of the colourful buttons.
This year in a team of five, we set out to investigate and experiment with the oneM2M standard, for our client InterDigital. Overall we were successful, here are our findings:
For the mass deployment of the Internet of Things to be a success, a global standard for machine to machine communication needs to become established. This report explores the oneM2M standard for Machine to Machine communication, researching its capabilities, how to make use of it, and ultimately builds systems upon it. Using them, data streaming, live video, and federation are put to the test.
This project is a oneM2M research project, with InterDigital as the client. They have created the oneTRANSPORT data marketplace, and this report with federate with their system, to demonstrate oneM2M.
After recent browsing, I had the idea to convert the Puzzling Stack Exchange into a book. Overall, the project was a success, however maths is currently not rendered as such. The book contains the top 100 questions and answers ever submitted to the site, formatted nicely to fit into a small A5 book(let).
I would like to thank the Puzzling Stack Exchange community for writing the puzzles, Stack Exchange for providing the data, and creativecommons.org for making this possible. Like the puzzles within, the book is licensed under the CC BY-SA 3.0 license. The book was created using the Stack Exchange Data Explorer to gather data, Python to parse and structure the data, and Pandoc to typeset as PDF. And thank you, the reader for reading this “book”. I hope you enjoy the puzzles. If you wish to contribute to this book, it can be found on my github.
Today I was playing a rather interesting variation of Cheat and Sh*thead with a group of friends, and thought it be worth sharing. But before doing so, I will fill you in on the rules of both games, for context.
Cheat
Setup: Shuffling a deck of cards and deal three to each player, leaving the pile in the centre of the table.
Gameplay: Players take it in turns to announce and play face down one or more cards of higher, lower, or equal value. If at any time a player suspects that the previous player cheated, they can loudly call CHEAT. All cards the player placed by that player are flipped. If the player has cheated, they pick up all of the cards, otherwise the accuser picks up all of the cards. The next player is whoever does not pick up cards. A player cannot call cheat on another if any cards have been placed atop of theirs.
Scoring: Once one player has placed all of their cards, a victor is crowned, and the game is over. If desired, count the number in each players hands to determine who came second, third, and so on.
Notes: The speed of the game depends on the group, but the faster they play, the easier it is to cheat. Unless the group is a hundred percent certain that a player is not cheating, it is worth accusing them after they place their final card. If desired, the game can continue after a player wins. However as players gather more and more cards, the game slows and lies become harder.
Sh*thead
Setup: The deck with Jokers is shuffled, and each player is given three face down cards. Then, each player is given an additional six cards, three of which much be placed face up atop their face down cards. Then the pile is placed in the centre of the table. The player with the greatest number of lowest value cards (excluding magic cards) in their hand starts. If multiple players draw, then the player who is first clockwise of the dealer starts.
Gameplay: Each player takes turns playing cards from their hands, face ups, or face downs - in that order. Cards must be of higher (Ace high), or equal value, but they must all be of the same value. After playing, a player draws back up to three cards if possible. Some cards are Magic and have special actions as denoted in the table below.
If four of the same value are played, then the pile is burnt and the current player get another turn. Jokers cannot be burnt in this manner.
If a player cannot legally place down cards, then they forfeit their turn and pick up the centre pile. Unless specified otherwise, magic cards can always be placed atop any other card, regardless of value.
The winner of the game is the first player to play all of their cards. However, the game can continue until all players bar one have played all of their cards.
Magic Cards: 2, Reset the current value. 7, Invisible, the next player must play equal or higher than the previous card. 8, Play Low, the next player must play lower than the previous card. 10, Burn, the pile is discarded and the player gets another turn. King, Change the direction of play. Joker, The next player cannot play a magic card.
Notes: Sh*thead can be played with any number of face down cards, as long as there are enough cards. Just ensure that each player is dealt that number plus three before choosing face up cards. If desired, players can choose different magic cards or different magic actions.
Cheathead
An amalgamation of both games. It is played like Sh*thead but instead of playing cards face up, they are placed face down so players must announce their actions. Players can call CHEAT at any time to force a check. As an optional rule, Jokers can be used as wild cards instead of magic cards for added confusion.
When making decisions, people negotiate to maximise utility and social welfare - agents are no different. Utilizing the GENIUS framework, this report tests time dependent concessions, and fitness proportionate selection putting them to test in a negotiation competition. The results are analysed and discussed.
After months of planningprocrastination, I have finally created a blog for this site of mine. I have used Jekyll site builder and Liquid templates to adapt this theme and add a blog. Hosting is provided by GitHub pages and I’ve bought a cheap .uk domain name.
London Fireworks 2018 LIVE - New Years Eve Fireworks: 2017 / 2018 - BBC One
In the coming days, weeks, whenever I will get around to adding new pages and backfilling old. But now with the technology in place, creating new pages is as simple as typing out markdown in Sublime Text, committing and refreshing the page. You can even subscribe to updates via RSS! Hope to see you soon!
Diving into Net Neutrality, this report will examine why it is so controversial. It will outline the social, economic, and technical arguments both for and against. Finishing with a discussion.
CCS Concepts: Social and Professional Topics → Net Neutrality.
General Terms: Networks, History, Politics.
Keywords: Net Neutrality, Free Speech, Internet, World Wide Web.
Introduction
We live in the information age. Today people can effortlessly research, create, and communicate with anyone on earth in a fraction of a second. But where did it begin?
The Southampton Code Dojo is a monthly event where keen computer science students meet, eat pizza, group up, and make things for a bit over an hour. At the start of the session ideas are proposed and voted on. Then, teams form typically on programming language choice, and everyone gets too work. At the end of the session, each team demonstrates. I have been attending for a while now, I love it. Hope to see you there!
Below is a list of some of the previous things I have worked on:
Let it Burn! - Using your flamethrower, wrack up points and burn the forest down.
Firework Simulator - Light up the sky with a fireworks display by dragging your finger or cursor across the screen.
With bash it is trivially easy to produce nice, colourful console output with the code below. Simply paste it into the top of your script, and then you can colour your text by just printing the variables.
For example, if you want bold yellow text with a red background use echo "${BOLD}${YELLOW}${BRED}Critical Warning!${CLEAR}". Additionally, you can ${ITALIC}, ${UNDERLINE}, ${INVERT}, or ${STRIKE} text as you see fit. Once you are done with formatted text, use ${CLEAR} to clear all formatting.
Lastly, ${RESET} and ${RULE} to reset the screen and create a horizontal rule. Vertical rules are left as an exercise for the reader.
#!/bin/bashCLEAR="\033[0m";BOLD="\033[1m";ITALIC="\033[3m";UNDERLINE="\033[4m";INVERT="\033[7m";STRIKE="\033[9m
RED="\033[31m"; GREEN="\033[32m"; YELLOW="\033[33m"; BLUE="\033[34m"; PINK="\033[35m"; CYAN="\033[36m"; WHITE="\033[37m"
BRED="\033[41m"; BGREEN="\033[42m"; BYELLOW="\033[43m"; BBLUE="\033[44m"; BPINK="\033[45m"; BCYAN="\033[46m"; BWHITE="\033[47m"
alias RESET='printf "\033c"'
alias RULE='printf %"$COLUMNS"s | tr "" "-"'
# Use $LINES and $COLUMNS to query console dimensions
███ is a great game. ███ demands that you play it. ███ can be played with any deck of cards from any game, assuming it has suits and values. For example, ███ works well when played with Star Realms cards, and ███ could work well with Magic, or even scraps of paper.
Rules
Deal out a number of cards to each player, the number doesn’t really matter in ███.
Players take turns placing down a card in the centre that is either higher or lower value and of the same suite, or the same value and any suite. This pleases ███.
If a player cannot play they must pick up. They have failed ███.
Shuffle the deck when it runs out. ███ must continue.
When a players hand empties, it is their turn to think of a new simple, secret rule. Contradictions please ███.
Do not explain this rule.
Enforce the rule viciously.
Do not mention the great ███.
Do not criticise ███.
Do not explain ███.
Do not argue about ███.
Do not make a mistake playing ███.
Do not fail ███.
Any mistake while playing ███ requires punishment, that player must pick up an extra card.
I decided to investigate Machine Learning using MATLAB.
Posterior Probability
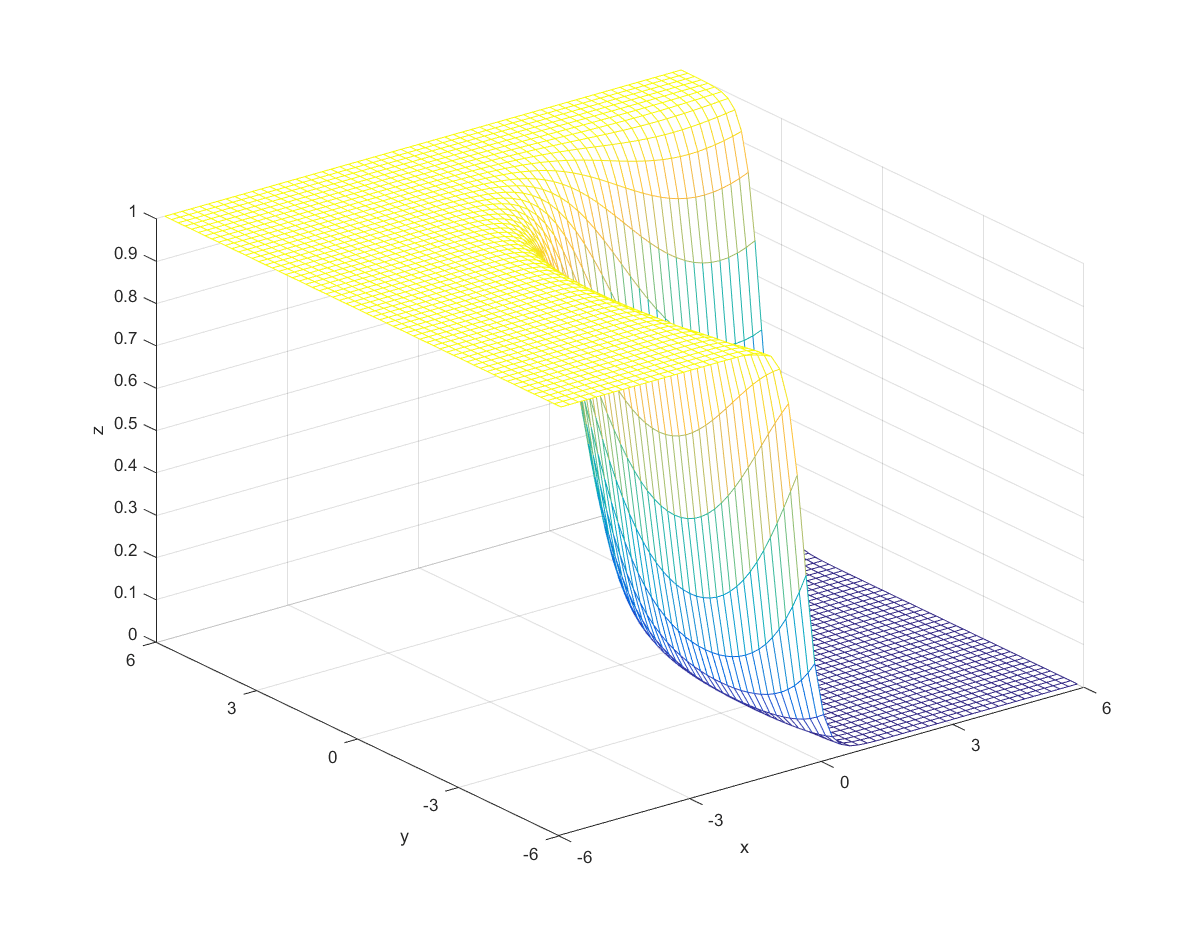
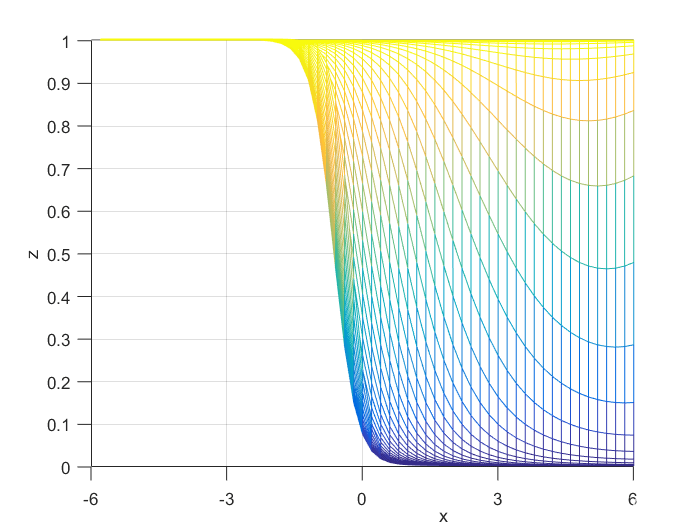
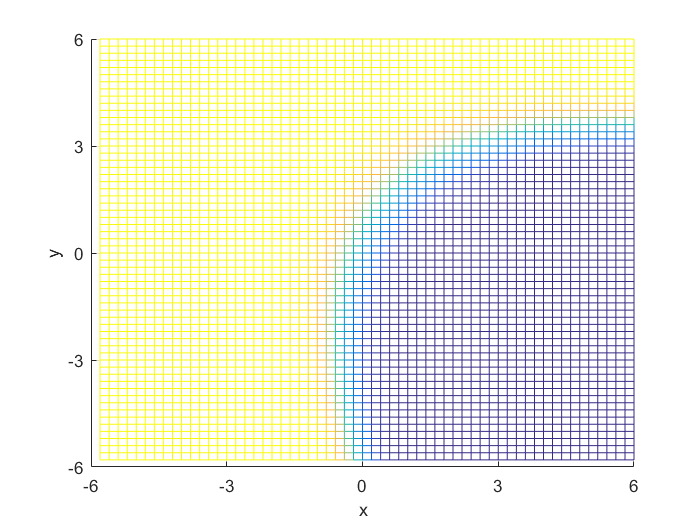
To compute the posterior probability, I started by defining the following two Gaussian distributions, they have different means and covariance matrices.
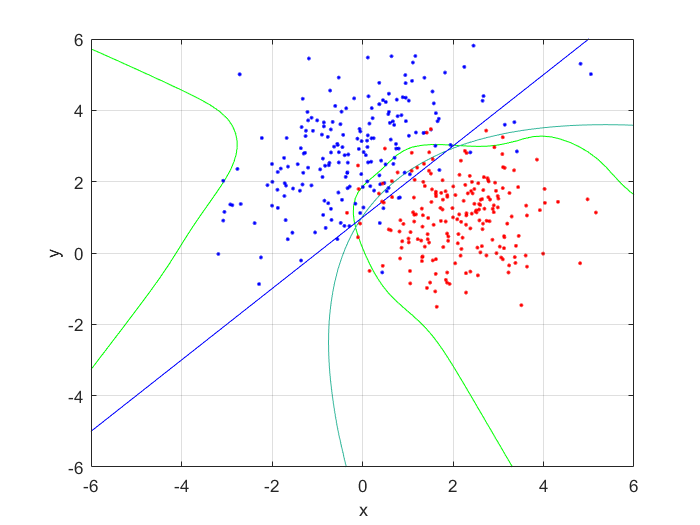
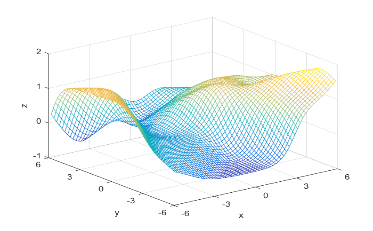
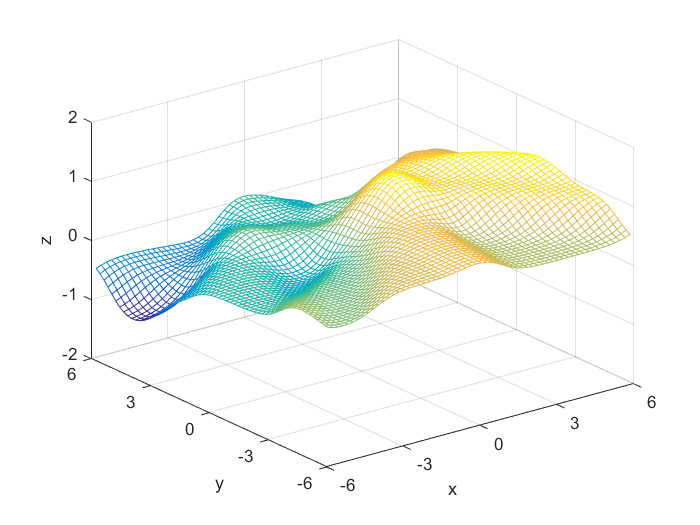
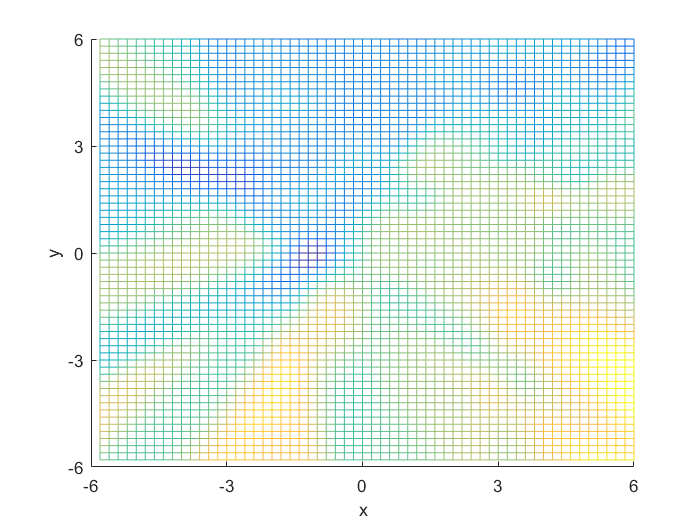
Using the definitions, I iterated over a N×N matrix, calculating the posterior probability of being in each class, with the function mvnpdf(x, m, C); To display it I chose to use a mesh because with a high enough resolution, a mesh allows you to see the pattern in the plane, and also look visually interesting. Finally, I plotted the mesh and rotated it to help visualize the class boundary. You can clearly see that the boundary is quadratic, with a sigmodal gradient.
Classification using a Feedforward Neural Network
Next, I generated 200 samples with the definitions and the function mvnrnd(m, C, N);, finally partitioning it half, into training and testing sets. With the first of the sets, I trained a feed-forward neural network with 10 hidden nodes; with the second, I tested the trained neural net, and got the following errors:
Normalized mean training error: 0.0074
Normalized mean testing error: 0.0121
These values are both small, and as the testing error is marginally larger than the training error, to be expected. This shows that the neural network has accurately classified the data.
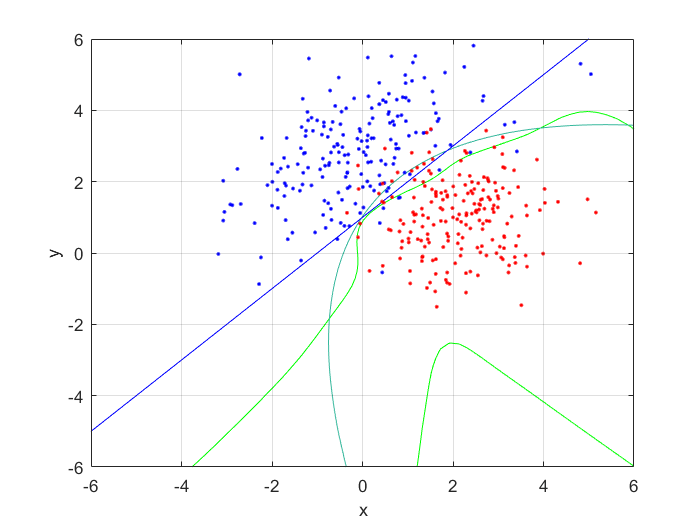
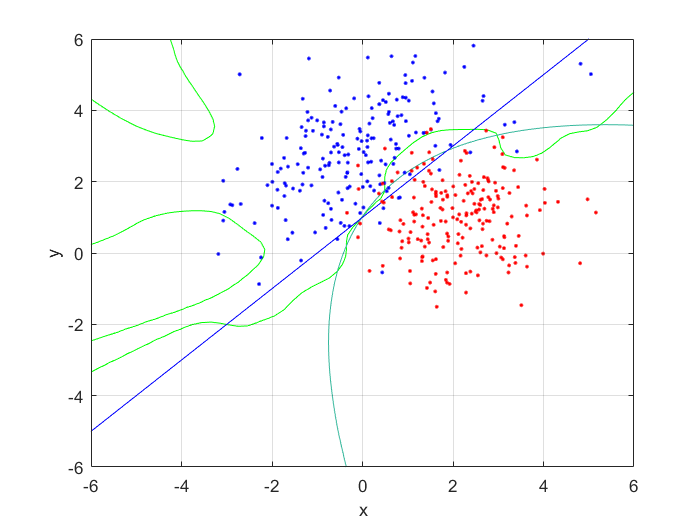
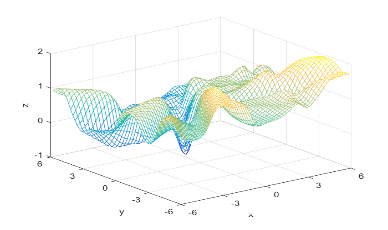
I compared the neural net contour (At 0.5) to both a linear and quadratic Bayes’ optimal class boundary. It is remarkable how significantly better Bayes’ quadratic boundary is. I blame both the low sample size, and the low number of hidden nodes. For comparison, I have also included Bayes’ linear boundary, it isn’t that bade, but still pales in comparison to the quadratic boundary. To visualize, I plotted the neural net probability mesh. It is interesting how noisy the mesh is, when compared to the Bayesian boundary.
Next, I increased the number of hidden nodes from 10, to 20, and to 50. As I increased the number of nodes I noticed that the boundary became more complex, and the error rate increased. This is because the mode nodes I added, the more I over-fitted the network. This shows that it’s incredibly important to choose the network size wisely; it’s easy to go to big! After looking at the results, I would want to pick somewhere around 5-20 nodes for this problem. I might also train it for longer.
Training Error: 0.0074 at 10 nodes, 0.0140 at 20 nodes, and 0.0153 at 50 nodes.
Testing Error: 0.0121 at 10 notes, 0.0181 at 20 nodes, and 0.0206 at 50 nodes.
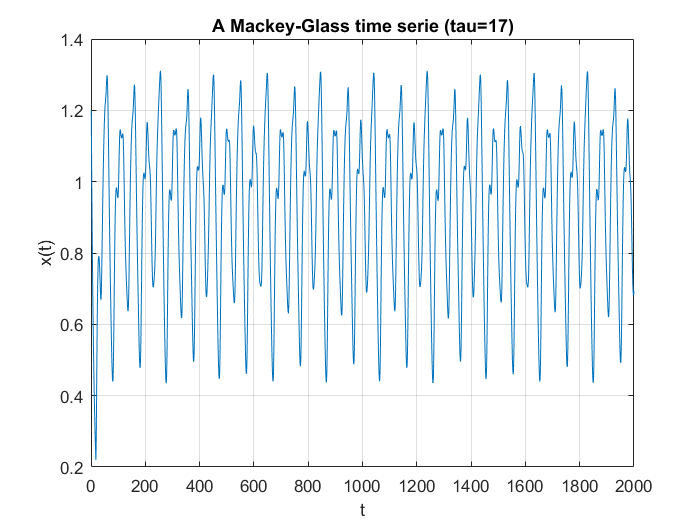
Macky-Glass Predictions
I was set the task of first generating a number of samples from the Mackey-Glass chaotic time series, then using these to train and try to predict their future values using a neural net. Mackey-Glass is calculated with the equation:
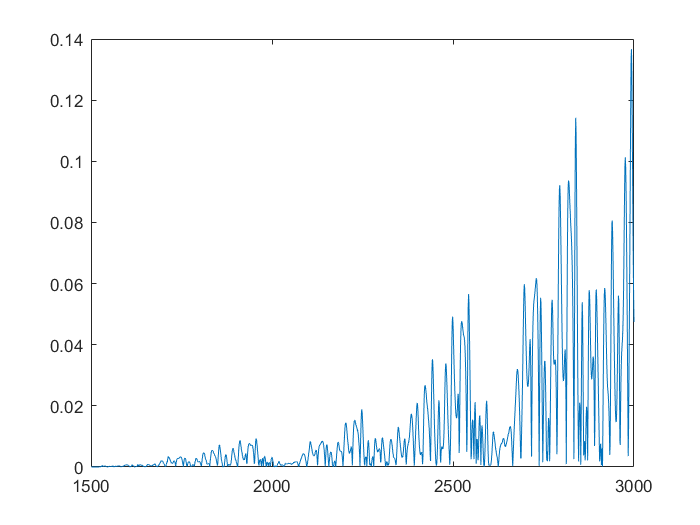
For the samples, I visited Mathworks file exchange, and downloaded a copy of Marco Cococcioni’s Mackey-Glass time series generator: https://mathworks.com/matlabcentral/fileexchange/24390. I took the code, and adjusted it to generate N=2000 samples, changing the delta from 0.1 to 1. If I left the delta at 0.1, the neural network predicted what was essentially random noise between -5 and +5. I suspect this was due to the network not getting enough information about the curve, the values given were too similar. You can see how crazy the output is in the bottom graph. Next, I split the samples into a training set of 1500 samples, and a testing set of 500 samples. This was done with p=20. I created a linear predictor and a feed-forward neural network to look at how accurate the predictions were one step ahead.
Normalized mean linear error: 6.6926×10^-4
Normalized mean neural error: 4.6980×10^-5
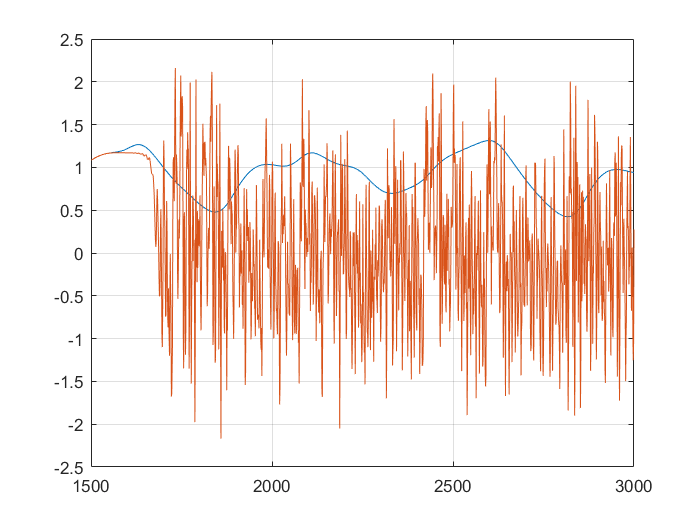
This shows that the neural network is already more accurate, a single point ahead. If you continue, feeding back predicted outputs, sustained oscillations are not only possible, the neural net accurately predicts values at least 1500 in the future. In the second and third graphs, you can notice the error growing very slowly, however even at 3000, the error is only 0.138
Financial Time Series Prediction
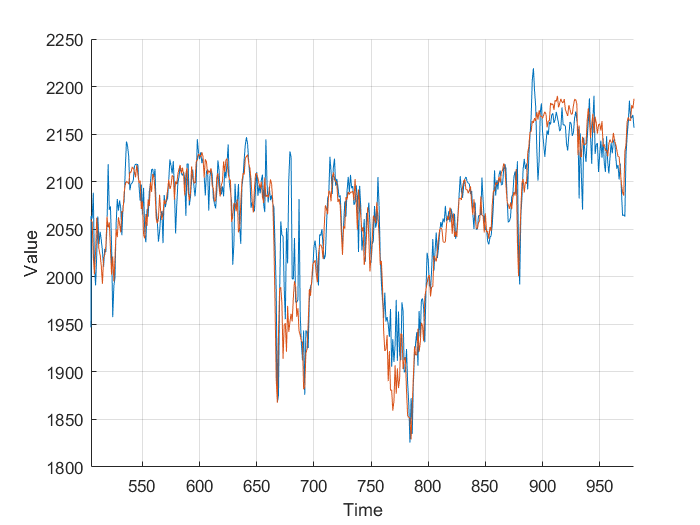
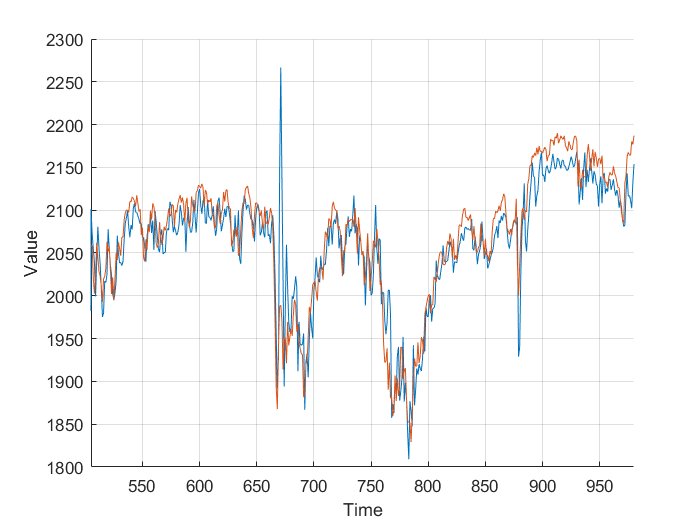
Using the FTSE index from finance.yahoo.com, I created a neural net predictor capable of predicting tomorrows FTSE index value from the last 20 days of data. To keep my model simpler and not over-fitted, I decided to use just the closing value, as other columns wouldn’t really affect the predictions, and just serve to over-complicate the model.
Feeding the last 20 days into the neural net produces relatively accurate predictions, however some days there is a significant difference. This is likely due to the limited amount of data, and simplicity of the model. It’s worth taking into account that the stock market is much more random and unpredictable than Mackey-Glass.
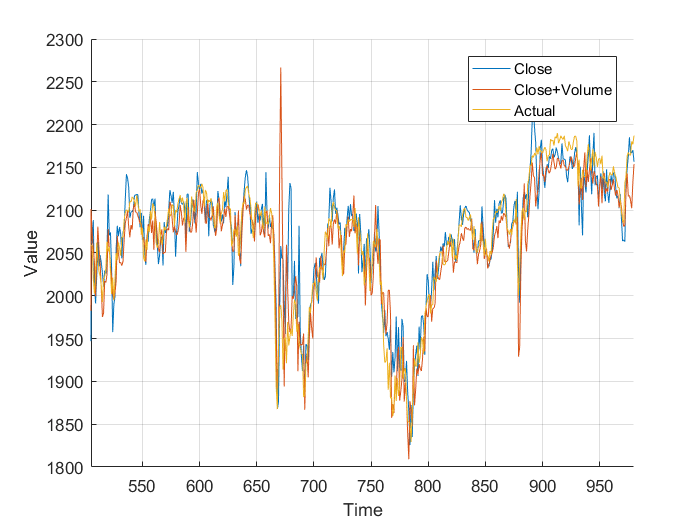
Next I added the closing volume to the neural net inputs, and plotted the predictions it made. Looking at the second graph, it’s making different predictions, which from a cursory glance, look a little more in-line.
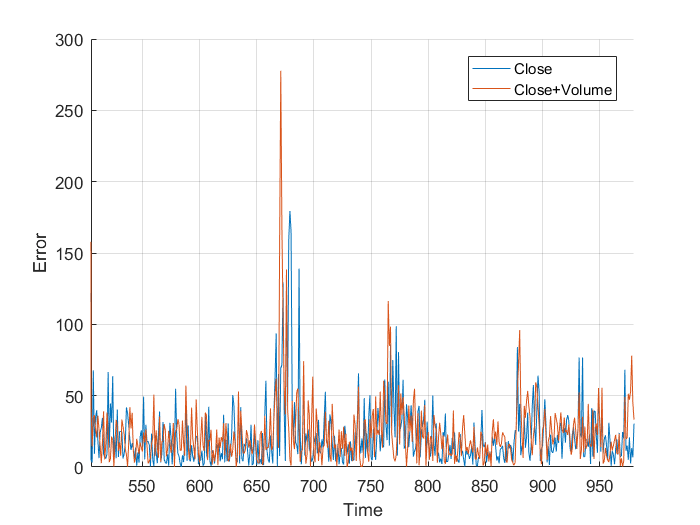
However, I wasn’t sure so I plotted them on the same axis, and, nothing really. It just looks a mess. Plotting the different errors again gives nothing but a noisy, similar mess. Finally, I calculated the total area, the area under the graph and got:
Normalized close error: 9.1066×10^5
Normalized close+volume error: 9.1180×10^5
This is nothing, a different of 0.011×10^5 is nothing when you are sampling 1000 points. It works out to an average difference of 1.131, or 0.059%. From this I, can conclude that the volume of trades has little to no effect on the closing price, at least when my neural network is concerned. All that really matters is the previous closing values.
Overall, there is certainly an opportunity to make money in the stock market, however using the model above, I wouldn’t really want to make big bets. With better models and more data, you could produce more accurate predictions, but you still must contest with the randomness of the market. I suggest further research before betting big.
This is the user manual for the Aqua programming language created as part of Programming Languages and Concepts. Visit the project on Github.
Aqua is a C-like imperative language, for manipulating infinite streams. Statements are somewhat optionally terminated with semicolons, and supports both block ( /* ... */) and line comments ( // ...).Curly brackets are used optionally to extend scope. Example code can be found in the Appendices.
Before continuing, it’s helpful to familiarise yourself with Extended BNF. Special sequences are used to escape.
Usage Instruction
Once the interpreter has been compiled using the make command, you can choose to run an interactive REPL or a stored program. Executing ./mysplinterpreterwith no arguments will start in an interactive REPL . You should save your program files as <filename>.spl and pass the location as the first argument to ./mysqlinterpreter. As data is read from standard in, you can pipe files in using the < operator, or pipe programs in using the | operator, allowing you to create programs that manipulate infinite streams.
Starting the interactive REPL: ./mysplinterpreter
Executing a saved program: ./mysplinterpreter <file> [ < <input> ]
Using infinite streams: <program> | ./mysplinterpreter <file>
Programs are executed in multiple stages:
Entire program is loaded into a string (Unix line endings required)
Program is lexed into Tokens
Tokens are parsed into an Abstract Syntax Tree (Left associative with the exception of lambdas)
On the first day of renting, My landlord gave to me: A junk pile in the garden.
On the second day of renting, My landlord gave to me: Two dark toilets, And a junk pile in the garden.
On the third day of renting, My landlord gave to me: Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the fourth day of renting, My landlord gave to me: Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the fifth day of renting, My landlord gave to me: Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the sixth day of renting, My landlord gave to me: Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the seventh day of renting, My landlord gave to me: Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the eighth day of renting, My landlord gave to me: Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the ninth day of renting, My landlord gave to me: Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the tenth day of renting, My landlord gave to me: Ten disturbances, Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the eleventh day of renting, My landlord gave to me: Eleven cracks tears and bumps, Ten disturbances, Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
On the twelfth day of renting, My landlord gave to me: Twelve quid less a day, Eleven cracks tears and bumps, Ten disturbances, Nine house showings, Eight worn out cabinets, Seven failed traps, Six rats a hiding, Five dank bedrooms, Four wonky desks, Three leaking sinks, Two dark toilets, And a junk pile in the garden.
Grabble is a fast-paced word game where players take it in turns to flip over tiles, form words, and steal words from other players. I was taught the game by Samson Danziger, and I am writing this as from a brief search, there is little information on it.
Setup
If missing a set of Scrabble tiles, any similar set of letter tiles will do, or they can bought for a few quid from many online retailers.
Every player grabs a scrabble tile from the bag, highest value starts, repeat until one victor.
Spread a set of scrabble tiles, one layer thick on a table.
Turn each tile over so it is face down.
It is recommended that a dot, question mark, or asterisk is added using a permanent marker to one face of each wild-card to reduce confusion when turned over.
Gameplay
Players turn over tiles one at a time trying to form words at least three tiles long, extend existing words, or steal words from an opposing player. When successful, that player is now the next player to turn over a tile.
Words must always be at least three tiles long. Shorter words do not count.
Words can be extended by adding tiles from the centre, combining with other words, or both. When combining words there cannot be any tiles ‘left over’, all tiles must make their way into the new word.
Words can be stolen (or protected) by rearranging their tiles into a new order. For example if a player claims TEA, another player can claim EAT. If the first player is clever they can then claim ATE to claim it back.
The game ends when all tiles are flipped and players agree that no more words can be improved or rearranged. This should not take longer than a couple of minutes. Players can enter and exit the game at any time, simply watch the game until they can get a word of their own. If they wish to leave, words remain in play and other players can steal the words when possible.
Block world is a simple 2D sliding puzzle game taking place on a finite rectangular grid. You manipulate the world by swapping an agent (In this case the character: ☺) with an adjacent tile. There are up to 4 possible moves that can be taken from any tile. As you can imagine, with plain tree search the problem quickly scales to impossibility for each of the blind searches.
It is very similar to the 8/15 puzzles, just with fewer pieces, meaning it’s simpler for the algorithms to solve. It’s unlikely any of my blind searches could solve a well shuffled tile puzzle with unique pieces, but I suspect my A* algorithm could. However, before doing so I would want to spend time improving my Manhattan distance heuristic, so it gave more accurate results over a larger range.
I decided to use Java to solve this problem, as I’m familiar with it and it has a rich standard library containing Queue, Stack, and PriorityQueue. These collections are vital to implementing the 4 search methods. You can implement the different searches differently, but the data structures I listed just deal with everything for you.
I produced a series of bash scripts to automate the process of pinging the list of websites. I choose bash as it is trivial to pipe the output from ping into various other command line programs such as: sed, gawk, and wget. As it was completely automated I decided to start early and just let it run. In total I pinged the top 100,000 websites up to 100 times each using script.sh (See Appendix A), recording useful statistics.
The script is very simple; a while loop to iterate over each site, and ping/ping6 piped into gawk to process the result. Gawk is very good at processing this sort of data, and more than fast enough to perform the task. The result was output to a large (11.1MiB) CSV file, with the IPv4 and IPv6 of each site, on separate lines.
As part of creating this script, I assumed that every site, if it exists would be able to respond within 10 seconds if it was online. If not, my script would timeout and assume the site was down. I feel this is a reasonable assumption as any remotely popular site should respond quickly, unless it’s currently being DDOSed. Another assumption I made is that any site I scanned would be able to withstand 5 requests per second. Even a raspberry pi is capable of serving 43 static pages per second1. As I sent a maximum of 50 requests, the brief period of slightly increased load should be negligible for any of the sites I scanned.
In hindsight, I would have combined both IPv4 and IPv6 into a single line from the start, as manipulating the data in excel is significantly easier to do if it is all on a single line. By that time I had already scanned the top 100,000 site’s so simply regathering the data was impossible. To fix this, I created combine.sh (See Appendix B) which simply echo’s the IPv4 line without a newline, then the IPv6 line with one. This is the reason I have some duplicated columns in my combined output. These are removed in Appendix D.
Whilst looking through the IPv6 column I noticed a very common prefix: “2400:cb00:”. After some research I discovered that this prefix belongs to cloudflare2. Using the prefixes I found on whatmyip.co3, I created a table mapping the hosting company to the number of sites it hosts. The results are impressive.
I decided to lookup the geolocation of each website. Looking around for a convenient database or API, I stumbled upon freegeoip.net4. It allows you to easily gather geolocation information for a specified IP in CSV form, perfect for my coursework. To retrieve this information using lookup.sh (See Appendix C) I self-hosted my own instance, then used cURL and a simple while loop to request and printf all the location information about each site to a file. I decided to record all the information given, to keep the script simple and retain all the information, to ensure I didn’t need to re-run the script.
Once the data was collected, it was time to head to Excel to analyze the data and draw conclusions. Having a large dataset let me create very good graphs, and draw good conclusions but was tedious to work with in Excel. Certain formulas, such as the ones used to create the Average Response Time per Country over Distance graph, managed to crash Excel numerous times and it even ran out of memory every now and then. In future when dealing with similarly sized amounts of data I would need to look into other graphing tools.
Results
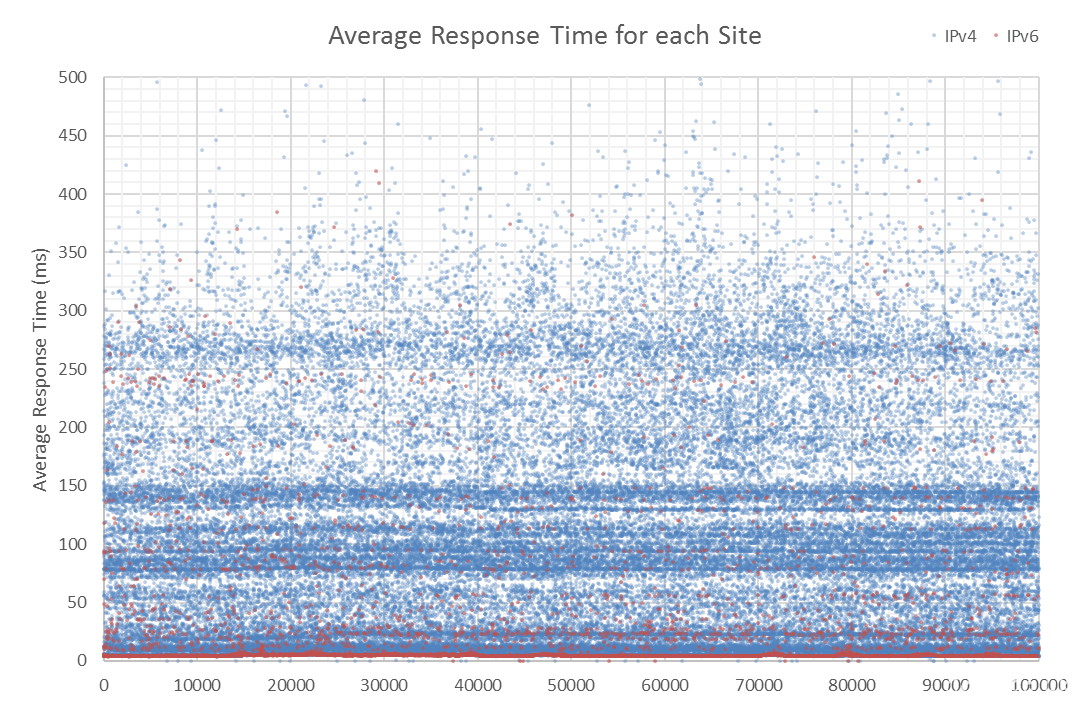
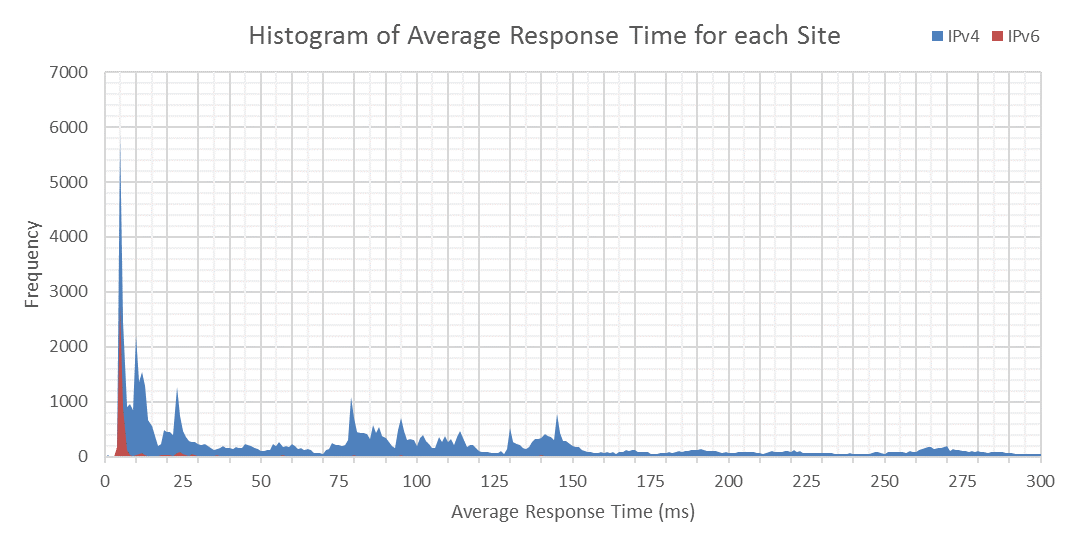
I decided to plot all 100,000 points as an X-Y scatter. In this, and subsequent graphs, IPv4 is blue and IPv6 is red. Immediately I noticed rather obvious bands of pings, which are shown in the Histogram, below. There are large peaks in the graph above. It’s interesting to note that despite the lower adoption of IPv6, the initial peak is half the height of IPv4. Past that, the frequency is low, indicating lower IPv6 response times.
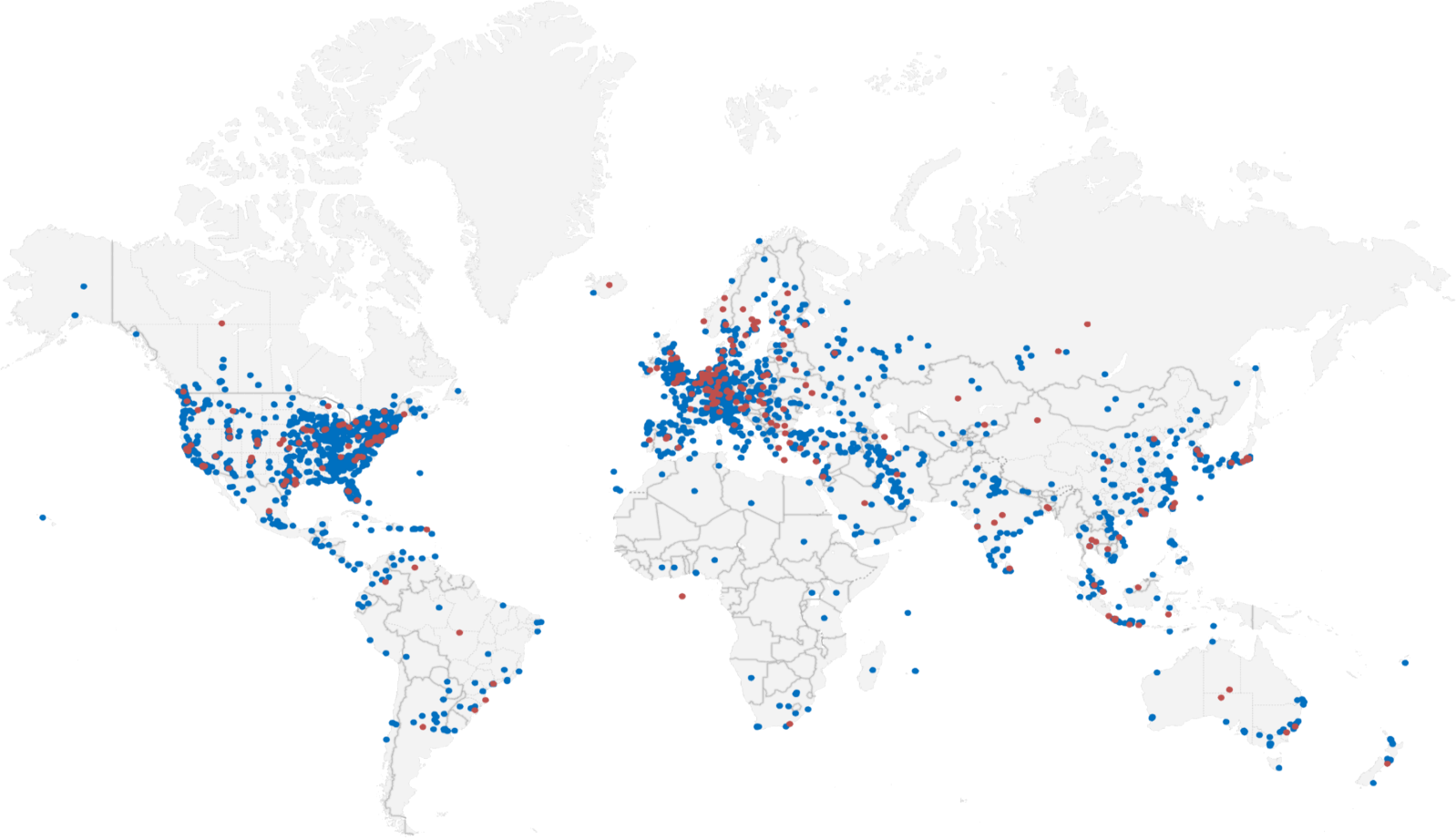
Thanks to CDNs and local sites, the top 1000 sites are concentrated around the 4-6ms mark with both averages trending slowly upwards. IPv6 is always significantly lower than IPv4 in the graph above. From a glance, you can see regions such as Africa, the Caribbean, and the Middle East without any IPv6 deployment. Sites are concentrated around the U.S.A, Europe and East Asia, with barren areas in-between.
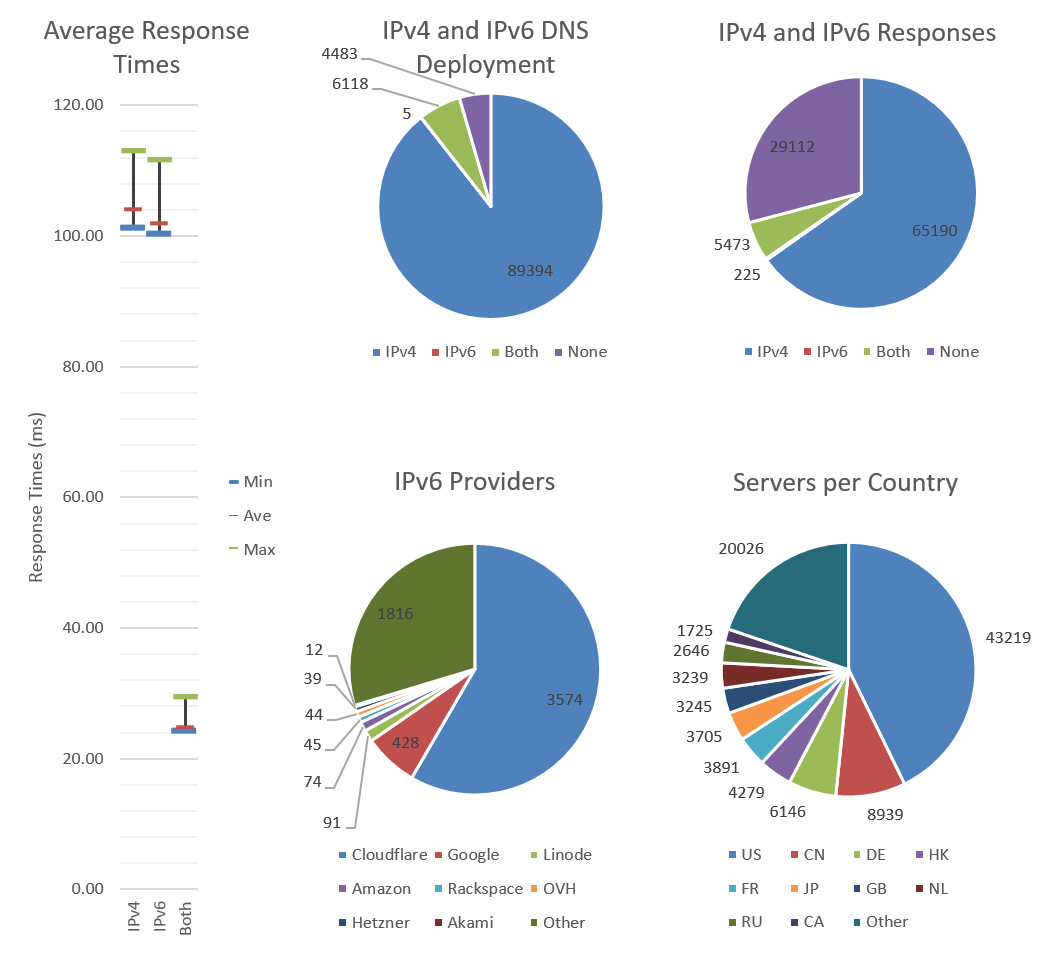
Average response times for IPv4 only and IPv6 only sites is roughly the same at about 104ms. The average min and max are largely identical as well; nothing surprising. On the other hand, the averages for sites running both IPv4 and IPv6 is very low in comparison – only 25ms compared with over 100ms! Now the question is, why are sites running both IPv4 and IPv6 significantly faster?
A Vast majority of 90% of the Internet is IPv4 only, with only 4.5% of sites providing both. In fact, more sites provide neither than both! It’s impossible to not have an IPv4 address and be truly connected.
A large number of the top 100,000 websites are either blocking ICMP echo requests (ping) or are simply offline. Alternatively they could only be only listening to a specific sub-domain. I didn’t check for this.
One reason sites that provide both IPv4 and IPv6 are faster, is that 65% of them are behind Cloudflare, or Google. Both have worldwide CDNs, and Cloudflare provides a free IPv6 gateway; allowing IPv4 only sites to be connected to using IPv6.
The U.S.A. is the world leader in number of hosted sites with 43% of the market. Comparatively, every other country is trailing behind with Canada at 9%, Germany at 6%, and Hong Kong at 6%. This is despite the existence of global CDNs.
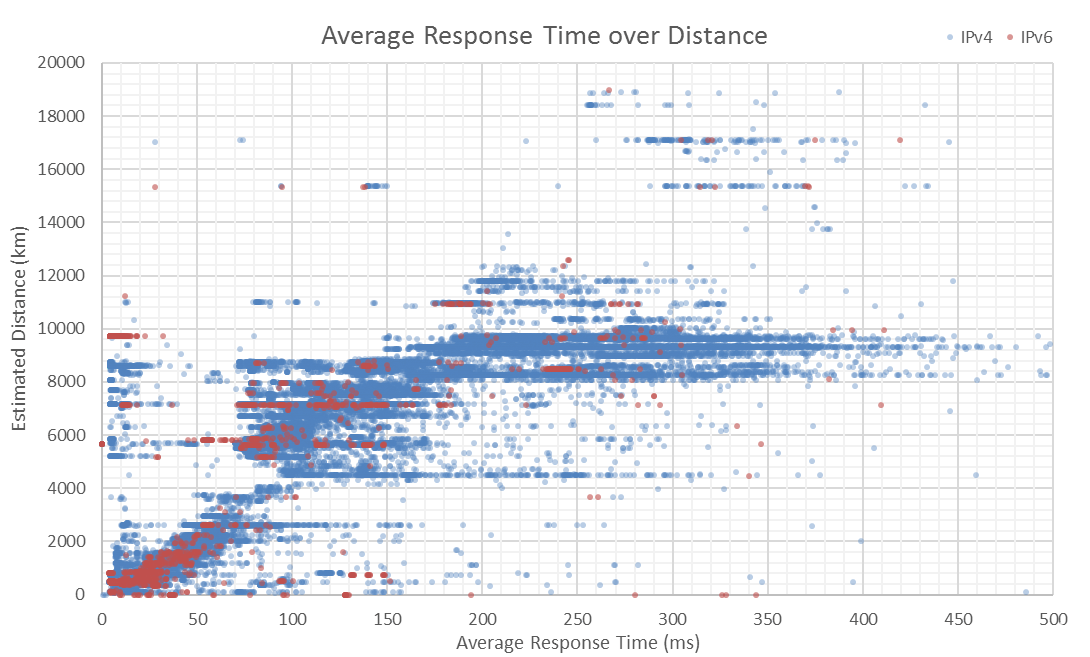
To test the geo-location accuracy, I potted estimated distance, over average response time. Sites above the diagonal are likely closer than their IP suggests. Sites below the diagonal simply have a poor connection. Besides a colourful graph, this shows the grouping of sites in different countries; explaining why there are so many peaks in the Histogram. There is a minimum amount of time it takes to connect to distant hosts.
Discussion
Limitations
I only ran the script once, and as the script took easily a week to analyze the top 100,000 sites, chances are the sites at the top had changed since the start. I could have gotten around this by parallelizing the script, or running it multiple times on a smaller set and taking an average. Parallelizing seemed too complex for the task at hand, and I didn’t really consider running it multiple times before it had almost finished analyzing. As I didn’t want to discard all the data, I decided to go ahead with the data I had.
The geo-location database I used isn’t 100% accurate - that is virtually impossible. You can see that it isn’t on the Average Response Time over Distance graph. Many sites are so significantly above the diagonal that the only way that the time would be possible is by breaking the speed of light; and indication that they are located much closer than their IP suggests. This is likely as common as it is, due the how exhausted IPv4 is, organizations are trading the limited number of IPv4’s that they have access to. This doesn’t really matter too much, due to the size of my data set. In future I could remove the outliers to produce cleaner results.
Speed
It is clear to see that sites that serve both IPv4 and IPv6 traffic are, on average, significantly faster than those that don’t (4 times faster on average). Every single graph I have produced shows this simple fact. I feel that this can be attributed to several factors:
Cloudflare and Google account for ~65% of all IPv6 traffic and both have global CDNs to ensure a fast and reliable connection. There are many more IPv4 sites that neither are associated with. Instead of connecting to a distance site, a CDN acts as a proxy, speeding up the time it takes to connect.
IPv6 isn’t widely deployed yet, with only 6% of sites serving it. Those 6% are usually the bigger websites; smaller sites may be stuck behind a single IPv4 address, in a data-center that doesn’t support IPv6.
Sites that serve both IPv4 and IPv6 traffic are concentrated in North America, Europe and East Asia – regions with geographically closer and better connected than the rest of the world. They are practically absent from regions such as Africa, the Caribbean and the Middle East. There is also little deployment in South America, West Asia and Oceania.
However, despite the fact that average response time for IPv6 is significantly faster than IPv4, it’s unlikely you’ll see any speed increase switching between IPv4 and IPv6 on a host that supports both. IPv6 is faster because the hosts that server both are well connected with fast response time, regardless of protocol.
Deployment
Despite the best efforts of organizations such as worldipv6launch.org, Cloudflare, and Google; IPv6 access is an afterthought. Despite claims of 500% growth since 2012, it’s 2015 and only 4.5% of sites support IPv6. As we go into the future, IPv6 deployment will surely grow as larger populations and the Internet of Things will strain the exhausted IPv4 pool even further. Until IPv6 is widespread, anyone with only an IPv6 address will be unable to connect directly to IPv4 only hosts, without the aid of a tunnel.
IPv6 isn’t evenly geographically distributed, compared with IPv4. If you’re in Africa, the Caribbean, or the Middle East, virtually no sites support IPv6. This suggests to me that the infrastructure required to support IPv6 just isn’t there.
Rank
Bigger sites are more likely to support and have a fast IPv4 and IPv6 connection than smaller sites. As you go through the different sites, the further down you get, the slower the site is to respond, on average.
From an underground Swiss bunker to all around the world; the World Wide Web has transformed from an experiment in academic distribution to the massively interconnected strength that we know today. While the current Web is relatively new, it has not only revolutionised the world, but promises to continue as our society strives towards the Internet of Things.
This report will untangle not only the history of the World Wide Web, but its many predecessors: designed and implemented, successful and not. It shall be accomplished by studying some of the attempts at webs from the past century; starting with the Mundaneum and ending with the current Web.
As the report approaches the end, it will look at the future of Web. Devices are becoming connected with smart devices such as phones, televisions and even thermostats sharing data with themselves, and their manufacturers. Privacy has been and will continue to be an important issue as greater amounts of data is shared.
To start the game, the player will press either button which draws the starting card; once drawn, the player will need to choose if they think the next card will be higher or lower than the current card and press the corresponding button. If they are right the green LED will light up, if not the red LED will light up and the buzzer will sound.
Shuffle a deck of playing cards without jokers, and deal out between players. All of the cards must be dealt out even if certain players have additional cards. Players then take it it turns placing down cards. Ace is high. The seven of each suite must be placed down first, and then adjacent numbers of that suite can be placed above and below it. If a player cannot play then the game skips to the next player. The game is over when a player places all of their cards, but can continue until all of the cards are placed.
Variants
Cheating Sevens
With the exception of seven, cards are placed face down, not face up, with players announcing the card. Players can lie so at any point any player can call CHEAT on the last card. It is turned over and if the accuser is wrong they simply skip their next turn. However, if they are right the next card is turned to check, and so on until either seven is reached, or a correct card is found. The accused then picks up all of the cards and play resumes.
Concurrent Sevens
Two players opposite each other play simultaneously. On their turn, they pick a card and place it face down in front of them. Concurrently, they flip and the card closest to seven is placed, with the other card returning to their hands.
Infinite Sevens
Infinite sevens is played with at least two decks of playing cards. Play is identical, except that Ace is simultaneously both high and low. This allows cards to wrap around crazily.
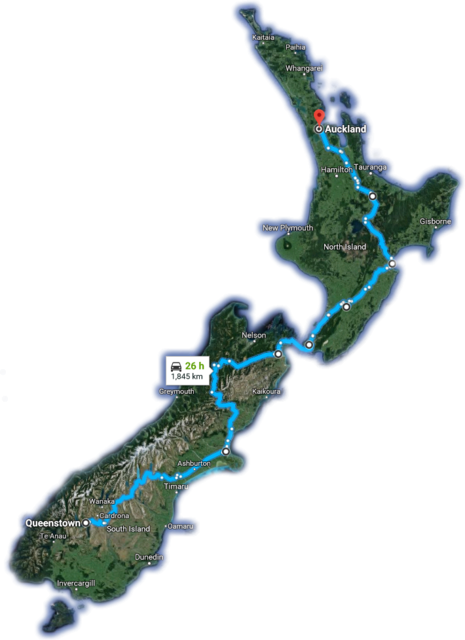
Hello, I am here to talk about my trip to New Zealand and my experiences visiting the country. I chose New Zealand as I have visited it many times and I feel that it would be interesting to discus.
The coastline around the country of Somalia is full of people committing acts of piracy and holding people hostage for a ransom. These are not pirates like you see in films but rather 20-35 year old Somalians with speedboats, GPS and modern guns. They attack cruise liners, oil tankers, fishing vessels and any other boat which they think they are capable of capturing. I am going to attempt to look for the reasons why high levels of piracy are taking place in the area and then why it is such a problem for people who need to travel or transport good by sea. To start will research Somalia then other aspects to work out why pirates have been such a problem in the Indian Ocean.
I believe that the reason pirates have been such a problem is because Somalia is a failed state and consequently very poor, turning people with boats into pirates due to the money involved.
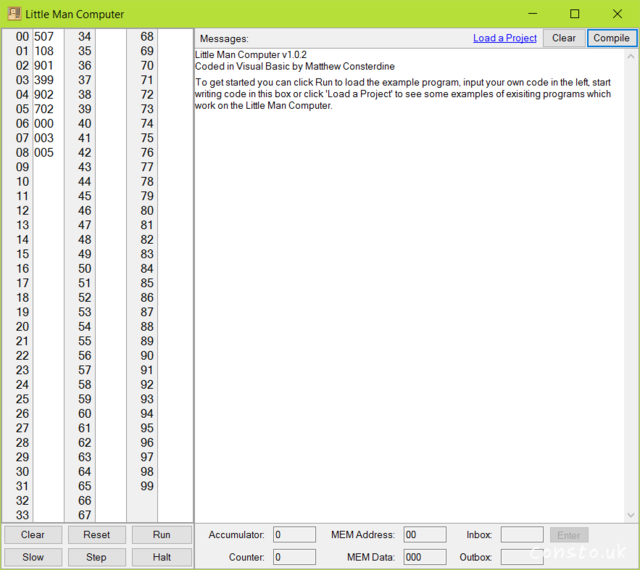
The Little Man Computer (LMC) is an instructional model of a computer, created by Dr. Stuart Madnick in 1965. The LMC is generally used to teach students, because it models a simple von Neumann architecture computer - which has all of the basic features of a modern computer. It can be programmed in machine (albeit usually in decimal) or assembly code.
For reference, here is some example code that takes numbers as input, and squares the result. Credit Wikipedia.
START LDA ZERO // Initialize for multiple program run
STA RESULT
STA COUNT
INP // User provided input
BRZ END // Branch to program END if input = 0
STA VALUE // Store input as VALUE
LOOP LDA RESULT // Load the RESULT
ADD VALUE // Add VALUE, the user provided input, to RESULT
STA RESULT // Store the new RESULT
LDA COUNT // Load the COUNT
ADD ONE // Add ONE to the COUNT
STA COUNT // Store the new COUNT
SUB VALUE // Subtract the user provided input VALUE from COUNT
BRZ ENDLOOP // If zero (VALUE has been added to RESULT by VALUE times), branch to ENDLOOP
BRA LOOP // Branch to LOOP to continue adding VALUE to RESULT
ENDLOOP LDA RESULT // Load RESULT
OUT // Output RESULT
BRA START // Branch to the START to initialize and get another input VALUE
END HLT // HALT - a zero was entered so done!
RESULT DAT // Computed result (defaults to 0)
COUNT DAT // Counter (defaults to 0)
ONE DAT 1 // Constant, value of 1
VALUE DAT // User provided input, the value to be squared (defaults to 0)
ZERO DAT // Constant, value of 0 (defaults to 0)
In the absence of any Windows desktop emulator, I created my own in .NET and here it is. View and download on GitHub.